
ECセラーのためのAI活用【完全攻略】〜理論から実践まで、この一冊でAIとの協業をマスターする〜
5.0
(5)
50%
(全員)
50%
(全員)
19,900円
19,900円

ゴマちゃん
2025/06/28
販売金額:
39,800
円目次
追記履歴
2025.07.11
実践編第10章 AIで魅せる!商品紹介動画の超効率作成術上級者向けコンテンツです。最低限、第8章の内容までを理解してから読むことをお勧めします。
自分で撮影した商品画像からシーン画像をAIで生成。シーン動画・ナレーション・BGMまで全てAIで生成します。
こんな方におすすめ!
せどり、転売、自社商品開発、輸入物販、OEM、中古販売、買取事業、輸出、メーカー仕入れ、卸仕入れ等
仕入れ・販売に限らずネット上で商品を仕入れたり、販売したりしている方におすすめです。
全体の約30%、72,000文字を無料公開中
EC物販におけるAI活用の可能性をより多くの方に知っていただくため、本書の一部を無料公開することにいたしました。
9つある実践例の1つ「AIで相場リサーチする」パートは全てご覧いただけます。
無料部分だけでも大ボリュームで、1日で読み切れるものではないかもしれません。
でも、ぜひ読み込んでいただき、皆さんのスキルアップに繋がると良いな、と思います。
現在、本書は最低価格で提供しており、段階的に値上げします。
トータル25万文字の執筆はほんとに大変だったので(笑)
「勉強になった」「もっと深く学びたい」
と感じていただけたら、ぜひご購入ください。
紹介報酬も設定していますので、参考になったらぜひ多くの方におすすめしてください。
EC物販でAIを使いこなす方法については、どの教材よりも詳しい自負があります。
「どんな内容が書いてあるか、もう少し知りたい」という方は、この先も読み進めてみてください。
9割以上がAIの使い方を知らない
「AIの登場で、世界が変わる」。
そう聞いた時、あなたはどんな未来を想像しましたか?
「商品説明文の作成が一瞬で終わる!」
「リサーチ業務から解放される!」
「売上が爆発的に伸びる!」…
そんな期待を胸にChatGPTを触ってみたものの、
「いまいち的外れな回答しか返ってこない」
「結局、自分で書き直すハメになった」…。
もし、あなたがそんな"違和感"を少しでも感じているなら、それは当然のことです。
なぜなら、あなたはAIという巨大な氷山の、まだ水面に浮かぶ一角しか見えていないからです。
なぜ、あなたのAIは本気を出してくれないのか?
では、なぜAIはあなたのビジネスの"本質"を理解してくれないのか?
それは、あなたがAIを「便利な道具」としてしか見ていないからです。
本書でくり返し語られるように、AIはもはや単なるツールではありません。
AIは、広範な知識を持つ一方で、あなたの現場のことは何も知らない「超優秀な新入社員」なのです。
この「新入社員」に、
「いい感じにやっといて」と曖昧な指示を出すのか、
それとも仕事の目的、背景、制約を丁寧に伝え、彼の能力を120%引き出す「いい上司」になるのか。
このマインドセットの違いが、AIを「オモチャ」で終わらせるか、「最強のビジネスパートナー」に変えるかの決定的な分かれ道です。
本書の特徴
AIという未知の領域を切り開くための「実践的ロードマップ」として、この教材を開発しました。
本書は、小手先のテクニック集ではありません。
AIの進化の歴史からその本質を理解する【理論編】と、具体的な業務に落とし込む【実践編】からなる、教科書と実践書のセットです。
理論編では、AIの歴史や深層学習の仕組み、各種ツールの網羅的な比較(LLM、画像生成、動画、音楽、音声、デザイン、検索、エージェントまで)を掲載。
AIとの正しい付き合い方を学びます。
そして実践編では、あなたのビジネスを加速させるための具体的な「武器(プロンプトテンプレート)」や手順を多数収録しています。
正しいAI活用で物販はどう変わる?
本書を手にすることで、あなたのビジネスはこう変わります。
膨大なリサーチに時間を溶かさずに済む
‥‥‥‥‥‥‥‥‥‥‥‥‥‥‥‥‥‥‥‥
- AIに相場リサーチをさせ、最適な価格設定のヒントを得る。
- 競合分析を自動化し、ライバルが気づいていない差別化ポイントを発見する。
- 廃盤・プレミア商品を発掘し、価格競争とは無縁の「お宝」を見つけ出す。
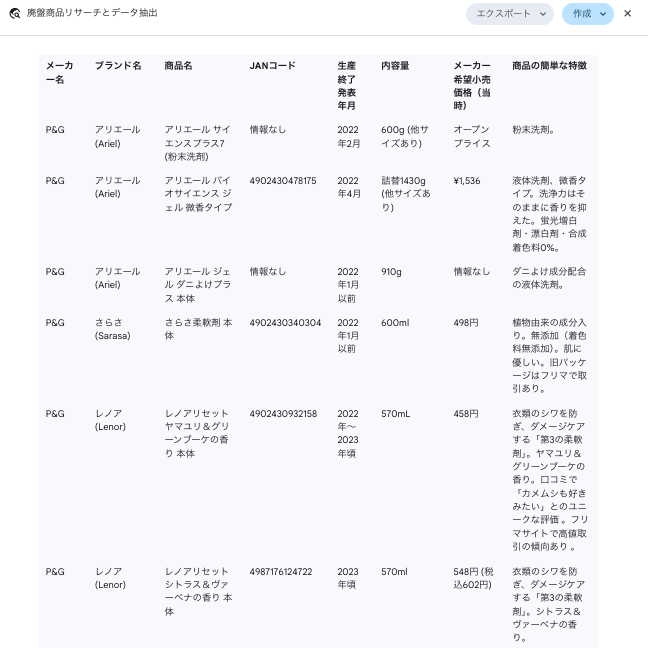
- JANコードをキーにECサイトを横断させ、
最安値の仕入先をリストアップさせる。 - これまで見つけられなかった、地域の優良な卸問屋を開拓する。
売れるコンテンツ作りに悩むことがなくなる
‥‥‥‥‥‥‥‥‥‥‥‥‥‥‥‥‥‥
- SEOに強く、顧客の心を動かす商品説明文を、AIと共に戦略的に作成する。
- 開封され、返信される、パーソナライズされた新規取引の依頼メールをAIに書かせる。
- スマホで撮った1枚の写真から、プロが撮影したかのような魅力的な商品イメージ画像を無限に生成する。

↓


あなたは「開発者」にもなれる
‥‥‥‥‥‥‥‥‥‥‥‥‥‥‥‥‥‥
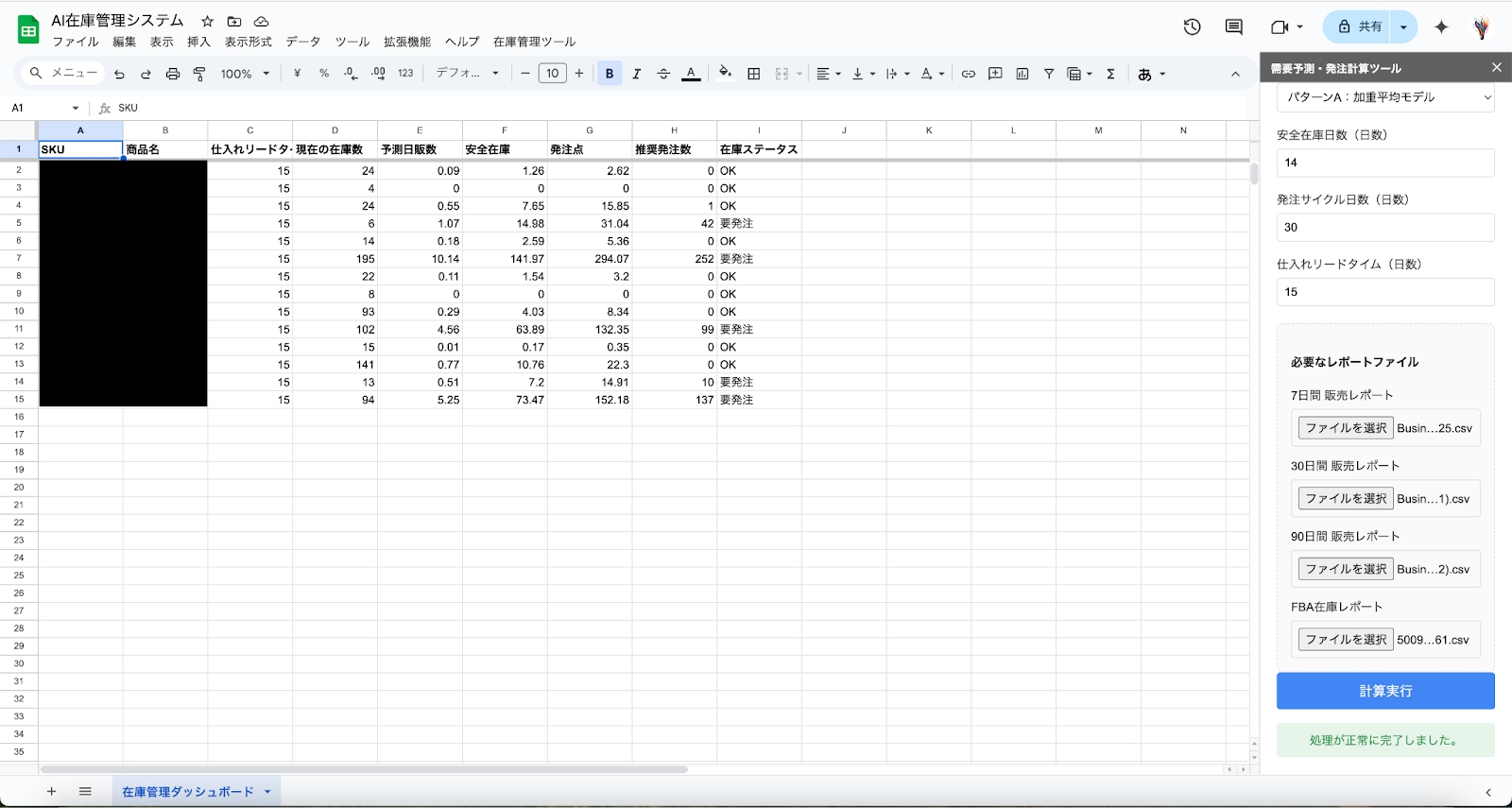
- プログラミング知識ゼロでも、AIにコードを書かせ、あなた専用の「在庫・発注最適化Webアプリ」を構築する。
9つの具体的な処方箋
本書は、あなたのECビジネスのあらゆる課題に対する具体的な「処方箋(=すぐに使えるプロンプトテンプレート)」です。「実践編」に記載している9つの実践例は下記のとおり。
①:AIで相場リサーチする
- 従来ツールとの違いを理解し、中古品の曖昧なコンディションもAIに対話的に判断させる方法。
②:競合分析を自動化する
- 具体的なケーススタディで、競合の強み・弱み、レビューの傾向を分析し、自社の差別化戦略を練る。
③:商品説明文を戦略的に作成する
- SEOキーワードリサーチから、Amazon、メルカリなど各プラットフォームに最適化された「売れる」文章を生成。
④:AIでプレミア価格商品を発掘!廃盤・生産終了商品リサーチ術
- 廃盤・生産終了品に特化したリサーチ術で、利益率の高いニッチ市場を開拓。
⑤:AIでコスト削減!EC横断・最安値仕入れリサーチ
- JANコードや型番を元に、Web全体から信頼できる最安値の仕入れ先を自動でリストアップ。
⑥:AIで開拓する地域の優良仕入れ先リサーチ
- オンラインでは見つからない、地域に根差したBtoBサプライヤーを発掘。
⑦:AIで攻略する!開封・返信される「新規取引の依頼メール」作成術
- AIに相手企業の理念を読み込ませ、心に響くパーソナライズされたアプローチメールを作成。
⑧:AI画像生成でクリック率が変わる!「売れる」商品画像の作り方
- YAML記法を使い、1枚の素材写真から魅力的なライフスタイル写真や広告クリエイティブを自在に生成。
⑨:AIにコードを書かせる!Amazon在庫・発注最適化Webアプリの構築
- GASを使い、Amazonの販売レポートから需要を予測し、最適な発注数を提案する自社専用ツールを開発。
本教材の対象外となる方
<注意点>
本書は、物販での収益を上げていない方が、収益を上げられるようになるというものではありません。金額の多寡は問いませんが、物販ですでに売上を上げている方を対象とした教材です。
記事全体の構成
- 目次 -
理論編:はじめに
本教材で得られるスキルの一例
なぜ“今”AIを学ぶべきなのか?
理論編第1章:AIの基礎理解
1-1.はじめに――AIが拓く未来と、その始まり
1-2. AIという言葉の歴史と本質
1-3. 第二次AIブーム:エキスパートシステムと機械学習の芽生え
1-3-3.水面下で進む「機械学習」の萌芽
1-4. 第三次AIブーム:深層学習と生成AI
理論編第2章:機械学習と深層学習の基礎
2-1. 機械学習とは何か
2-2. 深層学習(ディープラーニング)の仕組み
理論編第3章:生成AI(Generative AI)のしくみ
3-1. トランスフォーマー革命
3-2. 生成AIがもたらすインパクト
理論編第4章:AIを使いこなすためのマインドセット
4-1. AIを“超優秀な新入社員”として捉える
4-2. プロンプト作成の本質――“いい上司”が出す指示とは
理論編第5章. AIが苦手な領域と注意点
5-1-1.なぜ“一気に大量タスク”は失敗しやすいのか
5-2. 批判的視点と新規アイデアは苦手
5-3. “知ったかぶり”に要注意
5-4. AIに“夢を見すぎ”ない
理論編第6章:さまざまな生成AIとその使い分け
6-1. LLM(大規模言語モデル)
6-2. 画像生成AI
6-3. 動画生成AI
6-4. 音楽生成AI
6-5. 音声生成AI (音声合成・TTS)
6-6. デザインAI
6-7. 検索系AI
6-8. AIエージェント
実践編:はじめに
実践編第1章 AIで相場リサーチする
1-1.なぜ相場リサーチをAIでやるのか?
1-2.検索系AIの使いどころ──Perplexity / GenSpark / Felo / ほか
1-3.商品コンディション別・販売チャネル別の価格整理
1-3-2.実際のプロンプト例
1-4.AIごとの結果の違い──なぜ生じる?どう活用する?
1-5.相場リサーチのプロンプトの書き方
ステップ5.最終的に出力してほしい項目を整理
1-6. 相場リサーチのプロンプトテンプレート
1-7.1章のまとめ:AI相場リサーチのメリットと注意点
実践編第2章 競合分析を自動化する──商品開発や差別化のヒントを得る
2-1.競合分析をAIに任せる狙い
2-2.デモンストレーション:自社商品のアイデアと競合比較
2-3.AIに商品差別化プランを提案させる
2-4.競合分析時の注意点
2-5.プロンプトの作り方・テンプレート
2-6.実際に使ったプロンプト例
2-5.2章のまとめ:柔軟な情報収集で差別化の方向性を見出す
実践編第3章 商品説明文の戦略的作成:AI活用で売上を最大化する
3-1. なぜ商品説明文がECビジネスの成果を左右するのか?
3-2. AIライティングツール比較:最適な選択で成果を出す
3-3. SEOキーワードの基礎とリサーチツールの活用
3-4. 【実践編1】メーカー公式の情報を活用して商品説明文を作成する
3-5. 【実践編2】オリジナル商品/戦略的注力商品向け:AIを活用した徹底リサーチと深掘り商品説明文作成フロー
3-6. 【メルカリ効率化】AIテンプレで商品説明文を楽々作成
実践編第4章 AIでプレミア価格商品を発掘!廃盤・生産終了商品リサーチ術
4-1. リサーチの準備:対象カテゴリーとメーカーを選定する
4-2.【プロンプト設計編】AIに廃盤商品をリストアップさせる命令術
4-3.【実践編】特定テーマでの廃盤商品リサーチ・実演プロセス
実践編第5章 AIでコスト削減!EC横断・最安値仕入れリサーチ
5-1. 最安値リサーチの対象特定:JANコード・型番・商品名の戦略的活用
5-2.【実践プロンプト設計】ECサイト横断・最安値自動探索
5-3. AIリサーチの最終関門:人間による「目視検証」と最終判断
実践編第6章 AIで開拓する地域の優良仕入れ先リサーチ
6-1. リサーチ対象の定義:探すべき問屋の「業種」と「地域」を定める
6-2.【実践プロンプト設計】地域と業種を指定して問屋をリストアップさせる
6-3.【テンプレート】地域・業種別 問屋リサーチプロンプト
6-4. AI出力結果の精査とアプローチ候補の選定
実践編第7章 AIで攻略する!開封・返信される「新規取引の依頼メール」作成術
7-1. プロンプトの準備:AIに「心に響くメール」を書かせるための最高級の材料
7-2.【実践プロンプトテクニック】開封率を上げる件名と心を掴む本文の作成
7-3.【戦略的テンプレート】開封率を上げる新規取引依頼メール作成プロンプト
7-4.【実践編】AIによる「新規取引依頼メール」の生成プロセス
実践編第8章 AI画像生成でクリック率が変わる!「売れる」商品画像の作り方
8-1. 始める前の重要知識:AI画像生成の注意点と権利関係
8-2. 準備編:AIが最高の仕事をするための「素材写真」撮影テクニック
8-3.【実践編】YAML記法で作る「使用イメージ」生成プロンプト
8-4.【応用編】AI生成画像とキャッチコピーを合成して広告バナーを作成する
第8章のまとめ
実践編第9章 AIにコードを書かせる!Amazon在庫・発注最適化Webアプリの構築
9-1. アプリケーションの全体設計
9-2. 計算ロジックの定義
9-3.AIという開発パートナーへのマスタープロンプト
9-4.【実践編】AIによるアプリ開発とデプロイ
第9章のまとめ
実践編第10章 AIで魅せる!商品紹介動画の超効率作成術
10-1. なぜ「動画」なのか?- AI時代の新たなアプローチ
10-2. 動画制作の現実的なワークフロー設計
10-3. 【実践】AIによる動画制作の4ステップ
第10章のまとめ
理論編:はじめに
「AI(人工知能)」、特に「生成AI(Generative AI)」の進化は、いまやニュースやSNSをにぎわせる一大トレンドになっています。
多くのビジネスパーソンが「AIで一気に時短できる」「爆発的に売上が伸びるかも」と期待する一方、実際には「何をどう使ったらいいか分からない」とか「使ってみたけど微妙な結果で終わった」という声が溢れているのも事実です。
そんな中、物販事業において“生成AI”をどう使うかは、とても大きな可能性を秘めています。たとえば――
- 「商品説明文やセールスコピーを一瞬で大量作成」して売上アップ
- 「画像生成AIでインパクトあるビジュアル」を低コストで連発
- 「リサーチタスクを自動化」して面倒な市場調査や在庫分析を効率化
こうしたメリットを享受できるなら、あなたのビジネスは「時間の節約」×「売上向上」という理想的なレバレッジを得られるはずです。
しかし、AIはあくまでも“道具”です。使いこなすためには、以下のような課題をクリアしなければなりません。
- AI導入の“入口”が分からない
- 「ChatGPTに商品説明を書かせたら的外れだった…」
- 「実際に何をどう指示すれば良いの?」
- 誤情報や誇大表現のチェックが怖い
- 「AIが作った説明文をそのまま載せたら、根拠のない数字や違法表現が入っていた…」
- 「トラブルを防ぐには結局自分で調べ直すハメに」
- 新しい技術に振り回されて疲れている
- 「とりあえず流行りだから導入したけど、うまく使えず時間だけが過ぎた」
- 「長期的にどう活かすか分からない」
もしひとつでも心当たりがあるなら、本書はあなたの悩みを大きく解決する可能性があります。なぜならここには、実際に物販ビジネスでAIを活用した具体的な成功事例や、最短で成果を出すためのコツが詰め込まれているからです。
本教材で得られるスキルの一例
本教材のボリュームは膨大です。この教材を読み切るのはかなりの時間と根性が必要になります。しかし、読み切った頃には以下のようなリターンが得られるでしょう。
- 商品ページ制作が“数倍”ラクになる
商品説明・キャッチコピー・関連キーワード…これらを自動生成×ポイントだけ加筆で済ませるコツを習得。競合に差をつけるスピード感を手にします。 - 画像・動画コンテンツのクオリティが向上
生成AIを使った“バナー”や“イメージビジュアル”の作り方を理解すれば、外注費を大幅にカットしながら魅力的なクリエイティブを量産。 - リサーチとデータ整理が一気に自動化
「在庫回転率」や「生産終了品リスト」「市場価格の変動」など、面倒だった分析・調査をAI+簡単なスプレッドシート連携でほぼ自動化。 - AIの限界とリスク管理を知り、ビジネスの安定性を高める
誤情報の“見極め方”、法的リスクや規約違反を避けるチェックポイントなど、失敗を未然に防ぐノウハウを整理。
本書では、「AIの基礎理解」→「物販への活用テクニック」という流れで解説し、“超具体的”な事例と一緒にご紹介します。
なぜ“今”AIを学ぶべきなのか?
そうは言ってもなかなかAIスキルの獲得に時間を取れない人もいるでしょう。しかし、AIは”今”学ぶべきなのです。
AI領域は進化スピードが桁違いに早く、「後でゆっくり…」としているうちにビジネスチャンスを逃す可能性が高いです。
とりわけ物販の世界は自動化することで効率化可能な業務が多いため、AIを使うことで売上を何倍〜何十倍にも向上するチャンスがあります。
本書の内容を“今”吸収し、あなたのビジネスに落とし込むことで、競合が気づかないうちに「圧倒的な時短と売上向上」を実現する未来が見えてくるでしょう。
実は「AIを使いこなせるかどうか」は、今後5〜10年のビジネスを左右する大きな分岐点とも言われています。
この一歩を踏み出せるかどうかで、あなたが得られる成果やビジネスの可能性は大きく変わるのです。
では、魔法のようなAIの世界をお楽しみください。
理論編第1章:AIの基礎理解
1-1.はじめに――AIが拓く未来と、その始まり
現代において、AI(人工知能)がもたらすインパクトは計り知れません。
文章や画像、さらには音声・動画まで自動生成する「生成AI」の登場は、ビジネスや私たちの生活を大きく変えつつあります。たとえば、コンピューターに数行の指示を与えるだけで、見たこともない風景写真や小説のワンシーンのような文章が瞬時に生み出される――かつてはSFの世界だった現象が、いま私たちの身近に実現し始めているのです。
しかし、ここまでAIが発展するには、長い歴史とさまざまな試行錯誤がありました。
- 1950年代に生まれた「AI」という言葉が、なぜ世間を沸かせたのか。
- 研究者たちは、どんな夢と挫折を経験してきたのか。
- 「ブーム」と「冬の時代」を幾度かくぐり抜けた先に、いま目の前の“深層学習”や“生成AI”がどう結びついているのか。
本章では、AIという言葉が誕生した当初のエピソードを中心に、AIの歴史をざっくりたどります。歴史を知ることは、AIを単なる道具としてではなく、人間の壮大な夢と挫折がつまった“物語”として捉える助けになるでしょう。
1-2. AIという言葉の歴史と本質
1-2-1.ダートマス会議とAIの誕生1950年代のアメリカは、第二次世界大戦後の復興と成長期に入り、巨大なコンピューターが軍事や学術の現場に導入され始めた時代でした。そのころイギリスの数学者アラン・チューリングが、「機械が人間と同じように知的に振る舞うことは可能か?」という問いを世に投げかけました。彼は“チューリングテスト”という実験方法を提案し、もし人間の質問者が「相手が人間か機械か」区別できなくなるほど自然な応答ができれば、それは機械が“知能”を持っていると言えるのではないかという考えを示したのです。
具体的にチューリングテストを行う場合、質問者(審査員)は相手が見えない状態でテキストのやり取りを行います。一方の部屋には人間、もう一方の部屋にはコンピューターがいるのですが、質問者はどちらと会話しているのか知らされていません。もし、相手が機械であると見破れずに「これは人間だ」と思わせるほど自然な対話ができれば、そのコンピューターは“知能を持つ”と見なせるのではないか――これがチューリングの発想でした。当時はまだ性能も低く、実際にテストを完遂するほどのプログラムは存在しませんでしたが、こうした考え方が一部の若き研究者たちを強く魅了していきます。
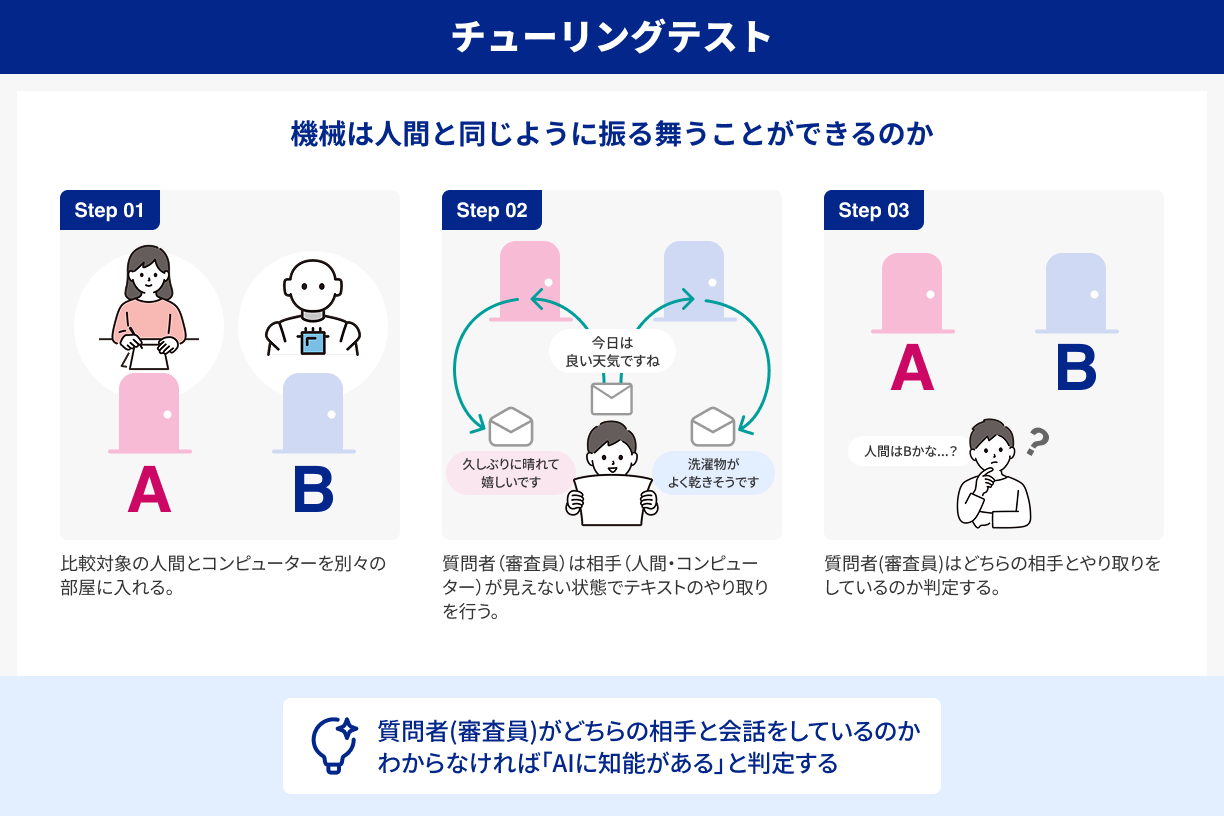
そして1956年、アメリカのダートマス大学で開催された小さな会議が、後に“AIの誕生”と呼ばれる歴史的なエポックとなりました。ジョン・マッカーシーやマービン・ミンスキー、クロード・シャノンなど、後に著名となる頭脳たちが集まり、機械は人間のように考えることができるのか、そしてそれを研究する分野を“人工知能(Artificial Intelligence)”と呼ぼうではないかと議論したのです。AIという言葉は、当時から「本当に人間の頭脳をシミュレートできるのか?」と疑われ、“うさんくさい”と揶揄されるケースもありましたが、彼らは「いつかチェスで人間を打ち負かすコンピューター」「ロボットが自力で学習する時代」などの壮大な未来像を語り合いながら、理想に向かって突き進む決意を固めていきました。

ダートマス会議を契機に、1960年代に入ると“AIなら何でもできるのではないか”という楽観論が一部の研究者や投資家の間で盛り上がり始めました。とりわけ象徴的だったのが、チェスや将棋、あるいは数理パズルなどの問題をコンピューターで解こうという試みです。当時の研究者は「問題のすべての可能性を網羅的に探索すれば解が得られる」と考え、いわゆる“全手網羅”型の方法を取っていました。少し規模が小さいゲームやパズルであれば、これはある程度成功し、コンピューターが人間に近いレベルで回答を出す場面も見られるようになったのです。
しかし、チェスや将棋のような複雑なゲームでは、可能な手の数が非常に多く、当時のコンピューター性能では到底読み切れませんでした。ほんの少し探索が深まるだけで、指数的に計算量が増大してしまい、現実的な時間内に処理しきれなくなります。軍事や宇宙開発の分野でも、一部でAI研究に多額の予算が投じられましたが、やがて「思ったほど成果が出ない」という厳しい評価が広がり、スポンサー企業や政府機関が「やはり実用にはまだ早すぎる」として資金を引き上げてしまいました。
当初は「AIならすぐにでも人間のように考えられる」と大きく期待されていたのが、実際にはチェス一つまともに読み切れない、ましてやロボットが人間並みに学習するなど夢のまた夢という状況だったのです。こうして1960年代末から1970年代にかけては“AIの冬”と呼ばれる停滞期に入り、多くの研究者が失意の中で資金不足に苦しみながら研究を続けるか、あるいはプロジェクト自体が凍結されてしまうケースも目立つようになりました。
それでも、この第一次AIブームで行われた研究や試みがすべて無駄になったわけではありません。チェスなどのゲームを使った“探索”や“推論”の技術は、その後の研究者が「どこにボトルネックがあるのか」を知るうえで大いに役立ち、また人工知能が「実現すればものすごい影響をもたらす」存在だという印象を世間に焼きつけた点でも大きな意味がありました。実際、チェスや将棋のコンピューター研究は、その後も細々と続けられ、数十年後にはさらに飛躍的な進化を遂げることになるのです。
かくして、偉大な研究者たちの野望が盛り上がった第一次AIブームは、計算能力とアプローチの限界を突きつけられて一時の終焉を迎えますが、これでAIの歴史が終わるわけではありません。すでに水面下では、まったく別の角度から「専門家の知識をシステム化する」アプローチが生まれようとしており、さらに「データから自動的にパターンを学習する」という画期的な構想も芽生えはじめています。それらが後に第二次、そして第三次AIブームにつながり、私たちがいま直面する“生成AI”時代へとつながっていくことになります。
1-3. 第二次AIブーム:エキスパートシステムと機械学習の芽生え
1-3-1.転機をもたらした新アプローチ「チェスやパズルの全手網羅」で大きく躓き、“AIの冬”と呼ばれる停滞期に陥っていた1960〜70年代。
そんな中、ある別のアイデアが注目を集め始めました。それは「優秀な専門家の知識をコンピューターに詰め込めば、素人でも専門家並みの判断ができるようになるのではないか」という発想でした。これがいわゆるエキスパートシステムです。
一方、同じ時代に「ルールを人間が書くのは限界がある」という問題意識から、“機械学習(Machine Learning)”の基礎を模索する研究者たちも現れ始めます。第二次AIブームと呼ばれる1980年代の盛り上がりは、この“エキスパートシステム”の部分的成功と、同時期にひっそりと芽吹いた“機械学習”の可能性が交錯して進展するところに大きな特徴がありました。
1-3-2.エキスパートシステムがもたらした部分的成功:①専門家の知識をルール化する
チェスのように問題を総当たりで解こうとするのではなく、「専門家(エキスパート)が頭の中で使っているルールをそのままコンピューターに覚えさせればいい」と考えたのがエキスパートシステムです。
医療であれば「こういう症状がある場合は××の病気を疑う」「熱が○○度以上あれば△△の検査を追加する」といった診断ロジックをデータベース化し、法律なら「契約書に○○という条項が含まれていたら△△法が適用される」などの事例をプログラムに覚えさせていくイメージです。
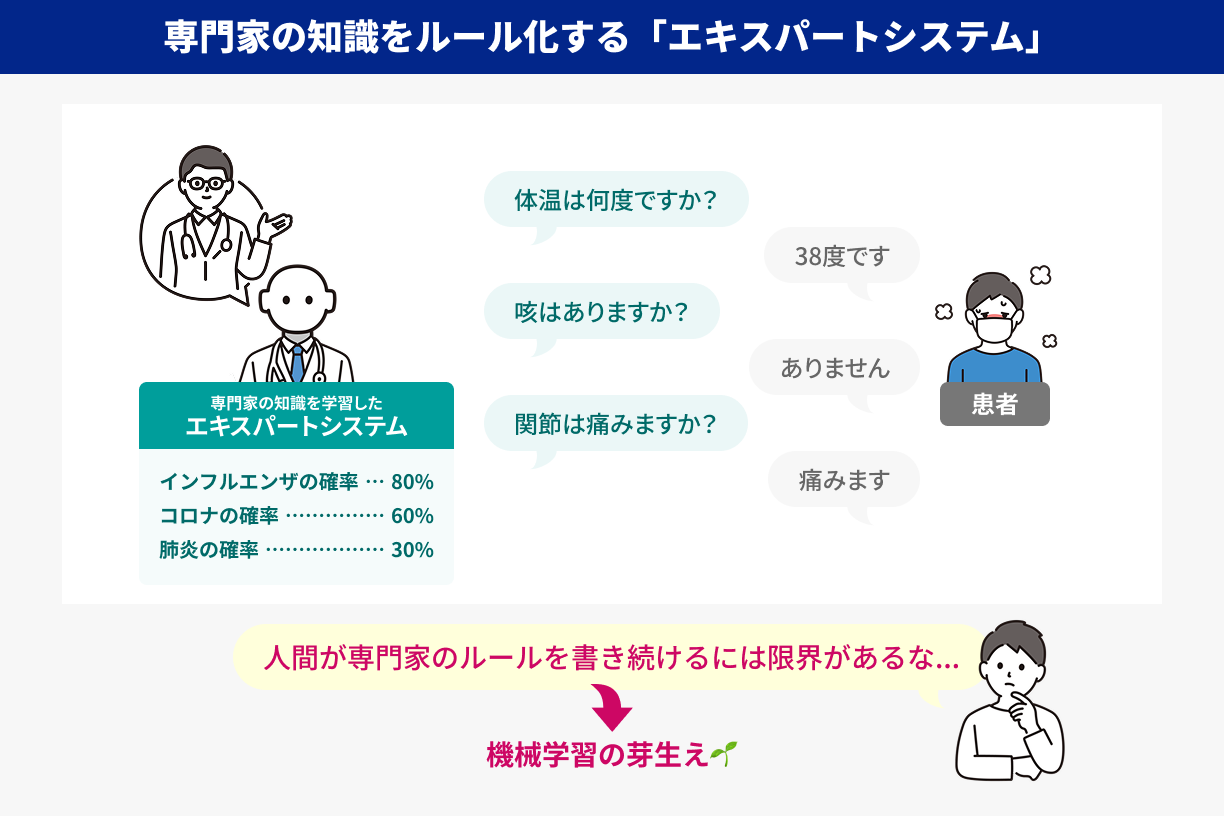
このアプローチは、総当たり的な網羅探索をする必要がなく、「すでに専門家が知っている判断基準」をルール化すればよいため、当時の計算機の能力でも比較的扱いやすいという強みがありました。特に1980年代の初頭には、企業や研究所が一斉に「エキスパートシステムこそAIの活路だ」という熱狂に包まれ、大きな投資が行われるようになります。
②DECのXCONと商業的インパクト
ビジネス上の代表的成功例として、DEC(Digital Equipment Corporation)が開発した“XCON”というエキスパートシステムが有名です。DECはコンピュータの受注生産を行っていましたが、顧客が望むパーツ構成を聞き取り、それを誤りなく組み合わせるのは非常に複雑なタスクでした。そこで、
「もしメモリが○○GBなら××のマザーボードを選択し、冷却装置は△△が必要になる」
といった多数のルールをXCONに覚えさせた結果、顧客への対応が劇的に効率化され、人的ミスが激減。企業として大幅なコスト削減と利益向上を実現するに至ります。
この成功は大きく報道され、「エキスパートシステムは本当に使えるAIだ」と一気に評価が高まりました。医療診断や製造業の生産スケジューリングなど、さまざまな分野にも同様のシステムが導入され始め、第二次AIブームは一挙に華々しい盛り上がりを見せることになります。
③エキスパートシステムの限界と挫折
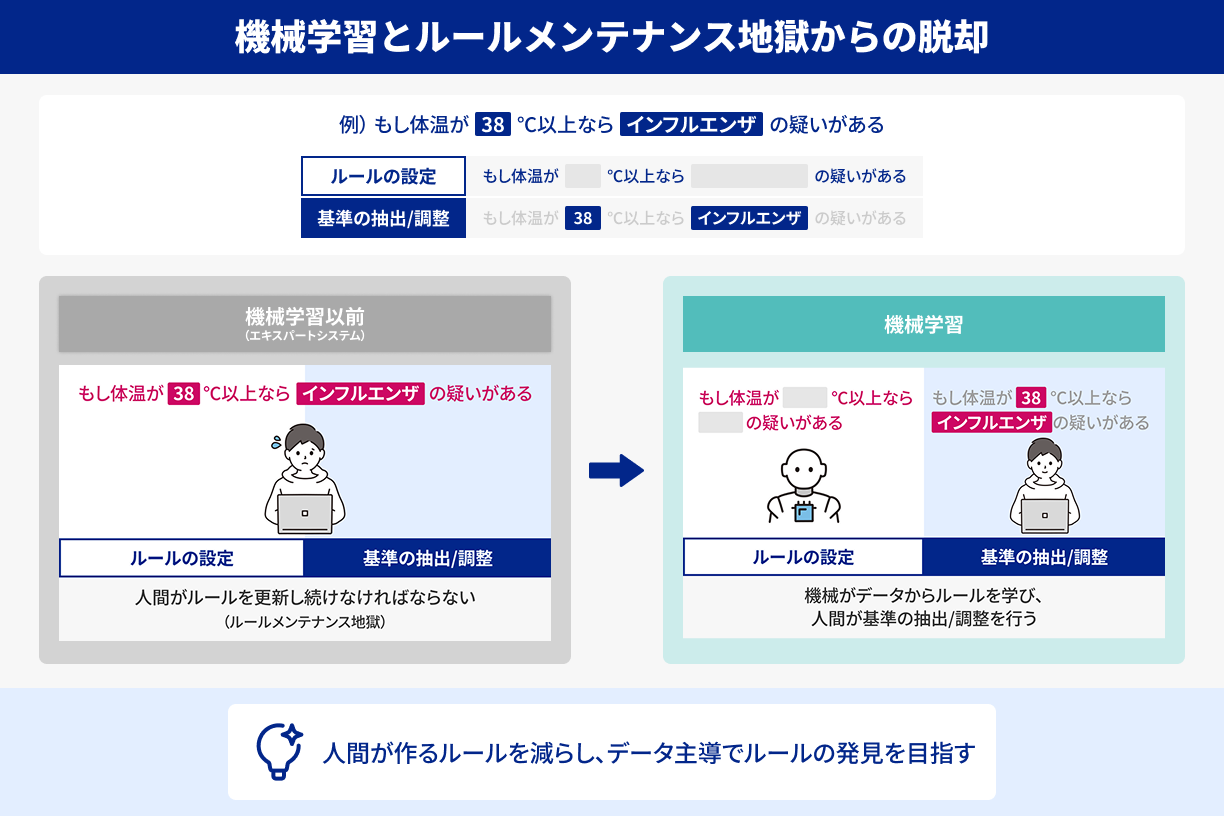
しかし、エキスパートシステムは「ルールを人間が追加・修正し続けなければならない」という欠点を抱えていました。たとえば医療分野で新しい症例や薬が出るたび、製造業で新パーツが登場するたび、ルールベースを更新しなければならない。実際にはそこに膨大なメンテナンスコストがかかり、しかも、すべての現実ケースをルール化できるわけでもありません。
結果的に、特定の領域では絶大な効力を発揮するものの、汎用的に活用できるAIにはならないと評価され、第二次AIブームも次第に失速に向かうことになります。
1-3-3.水面下で進む「機械学習」の萌芽
①ルールを全部書くのは無理? ならデータから学ばせよう
エキスパートシステムが抱えた「ルールメンテナンス地獄」の問題は、「それならコンピューターが自動でルールを見つけてくれればいいのでは?」という新しい発想を生む契機となりました。ここから、「機械学習(Machine Learning)」という考え方が徐々に注目され始めます。
機械学習では、医療データや製造記録、法律文書など、膨大な“事例”や“属性情報”をコンピューターに与え、そこから統計的にパターンを抽出しようと試みます。エキスパートシステムのように「もしこうなら△△」というルールを人間が手書きするのではなく、“データ”がコンピューターにルールを教えてくれるイメージです。
②決定木やルール学習の台頭
1980年代後半には、ID3やC4.5などの“決定木”アルゴリズムが研究されるようになり、これは「ある程度の属性データを入力すると、自動的に“もし○○ならば△△”といった判定基準を抽出してくれる」方法として話題になりました。たとえば医療データを大量に集め、「体温が○○度以上」「血液検査で××の数値が高い」といった条件の組み合わせから最終診断までを、機械が自動的に構築していくのです。
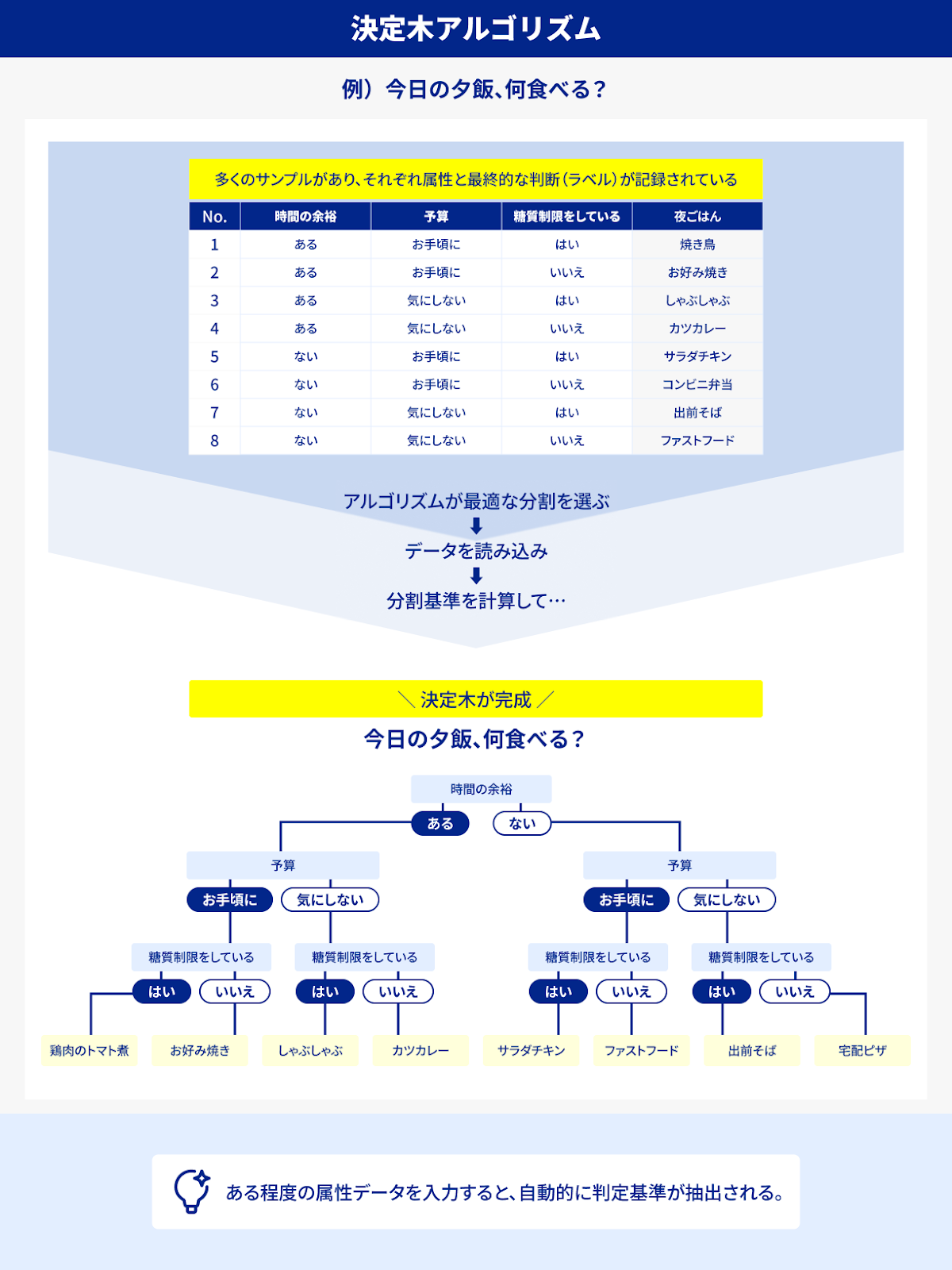
当時はまだパソコンの性能が低く、データもそれほど大量にはなかったため、爆発的な成功とはいきませんでしたが、「AIが自力で知識を発見する」という可能性は、後の深層学習ブームに通じる非常に重要な種となっていきます。
エキスパートシステムと機械学習の“萌芽”が重なった1980年代の第二次AIブームは、AIが「ビジネスで本当に成果を上げられるかもしれない」という期待を再度掻き立てた時期でもありました。
実際、DECのXCONのように、ルールベースで大当たりを引くケースも多々あった一方、メンテナンス作業の膨大さやルール化できない暗黙知の壁にぶつかって「やっぱり限界がある」と悟る企業も増えていきます。また、水面下で進んでいた機械学習も、本格的に開花するのはもう少し先のことでした。
とはいえ、第二次AIブームによって多くの企業がAI研究に投資を始め、人間とコンピューターが協力して何かを判断する仕組みが現場に導入され、大量のデータが電子化されていったのは後の大きな財産になります。その蓄積が、後に第三次AIブームの主役となる“深層学習”を大躍進させ、結果的に「生成AI」へと道をつなげていくのです。
1-4. 第三次AIブーム:深層学習と生成AI
1-4-1.大量データと高性能ハードウェアの出会い第二次AIブームが徐々に下火になった1980年代末から1990年代にかけて、AIの研究は決して止まっていたわけではありません。ただ、エキスパートシステムの限界が見え、機械学習もまだ実験的段階が多かったため、世間の大きな注目を浴びることはありませんでした。しかし、2000年代に入ってから事態が一変します。
インターネットの普及で世界中のデータがデジタル化され始め、“ビッグデータ”と呼ばれるほどの膨大な情報が集積されるようになったのです。さらに、CPUやGPUなどの計算処理能力が急激に高まり、多層にわたるニューラルネットワークを現実的な時間で動かすことが可能になりました。こうした背景が、第三次AIブームの大きな追い風となります。
当時までは、ニューラルネットワークは「理屈上は面白いけれど、計算量が多すぎる」と言われがちでした。しかし、ジェフリー・ヒントンやヤン・ルカン、ヨシュア・ベンジオといった研究者らが「ディープラーニング」(深層学習)を用いた手法を次々に提案し、コンピューターが多層の“脳のような回路”を通じて複雑なパターンを理解できることを示し始めたのです。
1-4-2.ImageNetコンペの衝撃とディープラーニングの躍進第三次AIブームを爆発させた象徴的な出来事が、2012年に行われた“ImageNet Large Scale Visual Recognition Challenge”という国際的な画像認識コンペでした。ジェフリー・ヒントンのチームが「ディープラーニング」を使ったモデル(通称:AlexNet)で圧倒的な成果を叩き出し、世界中の研究者や企業が「ニューラルネットこそAIの未来だ」と再認識したのです。

このモデルは、従来の手法よりも大幅に低い誤認識率を達成し、「いよいよ人間並み、あるいは人間を超える精度も実現可能」という期待感を一気に高めました。ちょうどその頃にはGPU(グラフィックス処理装置)を汎用計算に使う技術が進み、膨大な並列処理ができるようになったため、深い層(Deep)を持つネットワークを効率よく学習させられるようになったのです。
画像認識だけでなく、音声認識や自動翻訳などの分野でもディープラーニングが急速に浸透しはじめ、スマートフォンに搭載された音声アシスタントが「意外と正確に認識する」ことに多くの利用者が驚きました。企業はこぞってAI研究に投資を復活させ、「第三次AIブーム」と呼ばれる程の熱狂が再来したのです。
1-4-3.AlphaGoと人間超えのインパクト2016年にGoogle傘下のDeepMindが開発した囲碁AI「AlphaGo」が、トップ棋士のイ・セドル九段を4勝1敗で破ったニュースは、一般社会にも強烈な衝撃を与えました。囲碁はチェスや将棋に比べても桁違いに手数が多く、人間の直感的な判断力がものを言う競技だとされていたからです。
AlphaGoは、深層学習に加えて強化学習という手法を組み合わせ、大量の棋譜をベースに「自ら試行錯誤して上達する」仕組みを取り入れました。この勝利は、ディープラーニングが高度な意思決定や複雑な推論の領域にまで踏み込んでいることを世界に知らしめ、第三次AIブームは一挙に加速します。
第三次AIブームにおいて、深層学習は「データを正しく分類・認識する」という段階からさらに進んで、「何かを新しく生み出す」という段階にまで発展していきます。
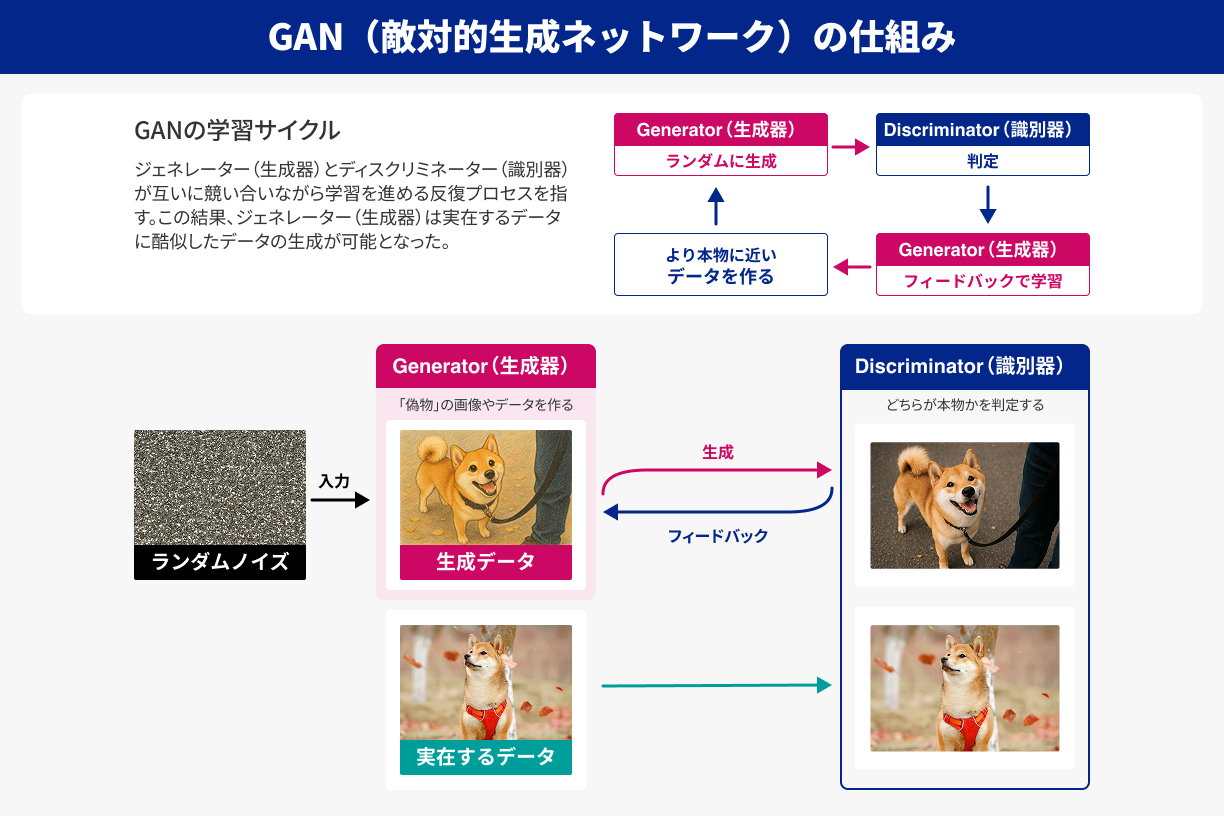
- GAN(Generative Adversarial Network)による“敵対的生成”という仕組みが登場し、架空の人物の写真やリアルなイラストなどを作る“画像生成”が一気に注目される。
- 大規模言語モデル(Transformer系)を使って、ChatGPTのように自然な文章を生成・要約・翻訳するシステムが急速に普及する。
- いまや、“生成AI”と呼ばれるこの潮流が、あらゆる分野のコンテンツ制作やビジネス戦略を塗り替えはじめている。
深層学習は、大量のデータを入力し、複数の層を通して特徴を抽出・組み合わせることで、高度かつ柔軟な判断や生成を可能にするという点が最大の特徴です。過去のAI手法とは一線を画し、「ルールをすべて書く必要も、全手を網羅する必要もない。あとは十分なデータと計算資源を与えれば、モデルが自ら法則や特徴を学習してくれる」という革命的なアプローチと言えるでしょう。
いま私たちが目にしている“生成AI”のブームは、こうした第三次AIブーム(深層学習)の延長線上にあり、その可能性はまだまだ広がり続けています。文章だけでなく、画像・動画・3Dモデリング、そして音声や音楽の生成まで、「機械がクリエイティブな領域を奪うかもしれない」という議論が真剣に交わされるようにもなりました。
理論編第2章:機械学習と深層学習の基礎
第1章では、AIの歴史を三つの大きなブーム(第一次・第二次・第三次)に分けて振り返りました。特に第二次AIブームで脚光を浴びたエキスパートシステムと、その後の機械学習の萌芽が、後の深層学習ブームへとつながる伏線になったことが分かりました。
しかし、「機械学習(Machine Learning)」という言葉自体は、現在ではAIとほぼ同義語のように使われることも多く、深層学習を含む広い概念として認識されています。たとえば「この問題はAIで解決できるか?」と問われれば、それはほぼ「機械学習か深層学習で解くのか?」と同じ意味合いになっているのが現状です。

とはいえ、機械学習と深層学習はアプローチや特徴量の考え方が大きく異なります。第2章では、まず「機械学習」の仕組みを整理し、人間が“特徴量”を設計するという発想を明確に理解したうえで、「深層学習(ディープラーニング)」がなぜ“自動的に特徴を抽出できる”のか、どんな原理で飛躍的な精度を実現したのかを解説します。
この章を読み終えれば、「機械学習と深層学習はどう違うのか」、そして「なぜ深層学習の登場が第三次AIブームを起こしたのか」がよりクリアになるでしょう。
2-1. 機械学習とは何か
2-1-1.人間が“特徴”を教える時代機械学習という言葉を聞くと、「AIが勝手にいろいろ学んでくれる」というイメージを抱くかもしれません。
ところが、実際の機械学習(特にディープラーニング登場前の手法)では、人間があらかじめ“どの要素に注目すればいいか”を教えてあげる必要があります。これが「特徴量(Feature)」という概念です。
たとえば、画像から“リンゴ”か“バナナ”かを判断する機械学習モデルを作るとします。従来の機械学習では、プログラマや研究者が「色の平均値や形状、端の丸み具合、赤色〜黄色の比率」などを“重要な特徴”として数値化し、その数値群をモデルに入力していました。「リンゴっぽい形状か?」「バナナっぽい色合いか?」といった基準を人間が最初に設計しなければ、機械は何を見ればいいのか分からないのです。
同じことはテキストでも言えます。文章分類をやる場合、「文中のキーワード頻度」「特定フレーズの出現」などを特徴量として設計し、それをもとに「スパムメールかどうか」などを分類するモデルを学習させる、という流れが一般的でした。

このように、「人間が設計した特徴量」を入力して学習する手法が、ディープラーニング以前の機械学習の大きな特徴であり、同時に大きな制約でもあったのです。
機械学習には、教師あり学習と教師なし学習という2つの大きなアプローチがありますが、いずれの場合も「何を見ればいいか(特徴量)」は人間が定義する必要があります。たとえば教師あり学習では、画像に「ラベル」が付いたデータを見せながら「ここを注目すれば分類しやすい」という特徴量を使いモデルを作りますし、教師なし学習では「ラベルなしのデータ」からクラスタ分けを試みる場合でも、「この次元の数値を使えば、グループができるかも」という発想を人間が与えます。
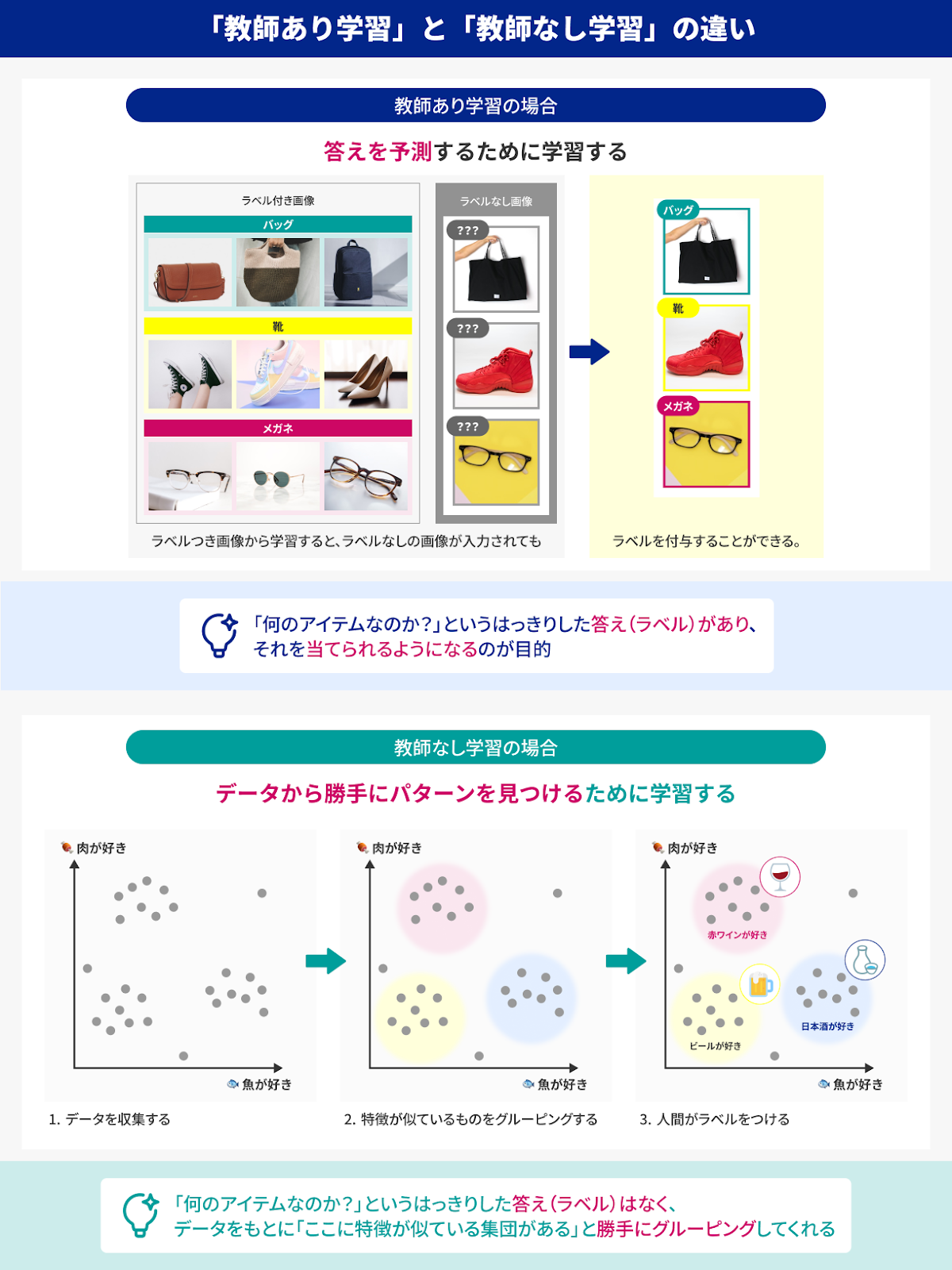
どちらにしても、機械学習が正しく働くには、人間が「どんな特徴が判断に役立つのか」をある程度わかっている必要があるため、いわゆる「職人芸」的な要素が強かったのです。経験豊富な研究者やエンジニアが特徴量設計を上手に行えば高い精度を出せる反面、間違った特徴量を選ぶと性能が伸びず、何度も試行錯誤することになります。
機械学習は、特徴量さえ上手に設計すれば、さまざまな業務で実用化されてきました。たとえば、画像分類では辺の輪郭や色の分布などが特徴量となり、ある程度は人間が「こういう辺やコーナーを検出しよう」と設計します。ECサイトのレコメンドシステム(“この商品を買った人は〇〇も買っています”)では、ユーザー行動ログを特徴量として用い、“類似行動”を見つけ出す仕組みを構築。需要予測や売上予測でも、日付や店舗ごとの売上など、人間が定義した数値をアルゴリズムに入力してモデルを学習させ、先の値を推測します。
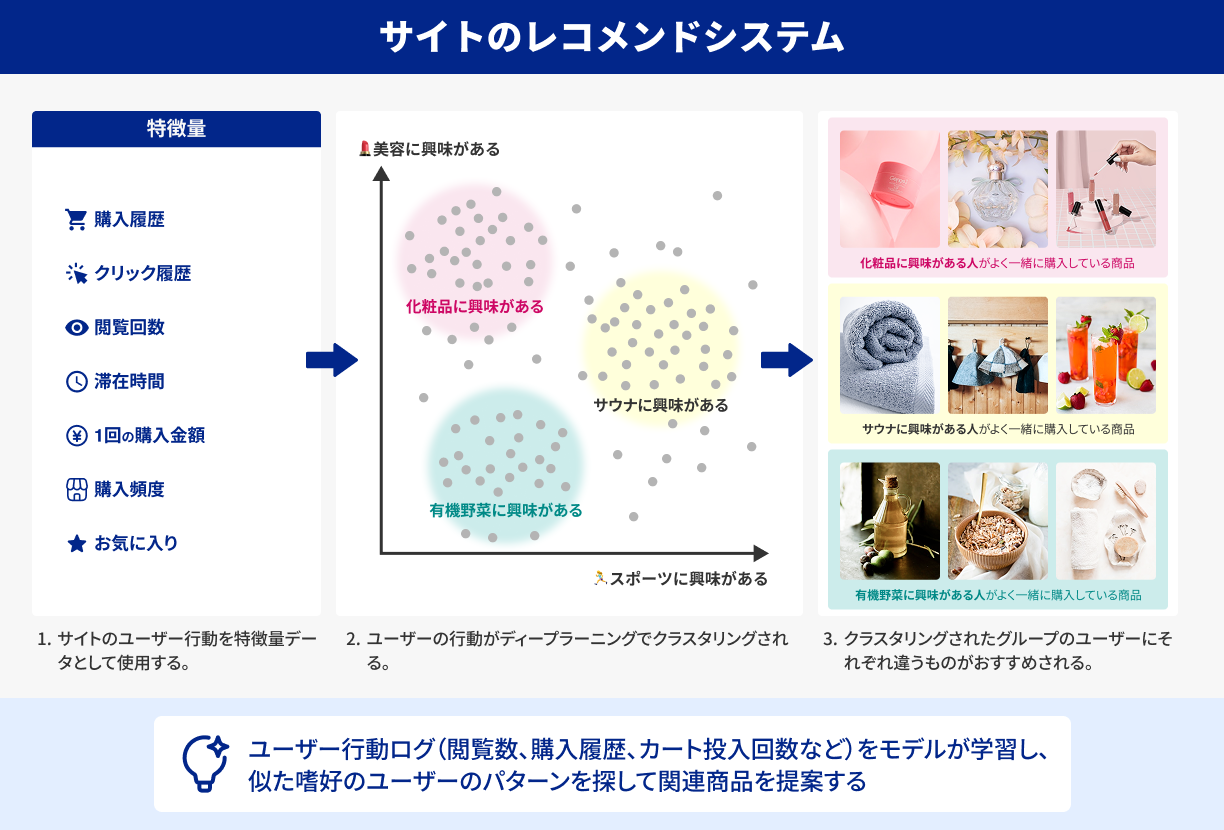
これらの手法が第二次AIブームで部分的に花開き、現在でも機械学習として多くのビジネスで使われ続けていますが、やはり「どんな特徴を使うか」を人が考える負担は大きいものでした。
人間が特徴量を設計するということは、開発者が「何が重要か」を先に理解していなければならないという意味でもあります。もし本当に重要な要素に気づけなければ、モデルがいくら学習しても精度が伸びないという悩ましい状況に陥ります。
また、現場によっては「専門家にしかわからない暗黙の勘所」があったり、「数値化しにくい要素」があったりします。こうしたハードルを乗り越えて高精度のモデルを作るには、かなりの試行錯誤と専門知識が必要です。
ここに“深層学習(ディープラーニング)”が登場し、「そもそも人間が特徴量を決めなくても、機械が自動的に特徴を見つけられる」というアプローチが実現した時、AIの可能性は一気に広がったわけです。ディープラーニングは次の節(2-2)で扱いますが、まずは従来の機械学習が「人間が特徴を与える」という仕組みを前提に動いていたことを押さえておきましょう。
2-2. 深層学習(ディープラーニング)の仕組み
2-2-1. まずは“ニューラルネットワーク”って何?機械学習の発展の中で、特に大きな飛躍をもたらしたのがニューラルネットワークを使うアプローチです。そもそもニューラルネットワーク(NN)は、人間や動物の脳神経回路をまねたモデルとして1950〜60年代から研究されていました。当時は計算能力の不足もあって、数層のネットワークを組む程度にとどまり、あまり精度を出せなかったのですが、理想としては「脳のように大量のニューロン同士が結合し、データから自動でパターンを学ぶ」という壮大なコンセプトを抱えていたわけです。
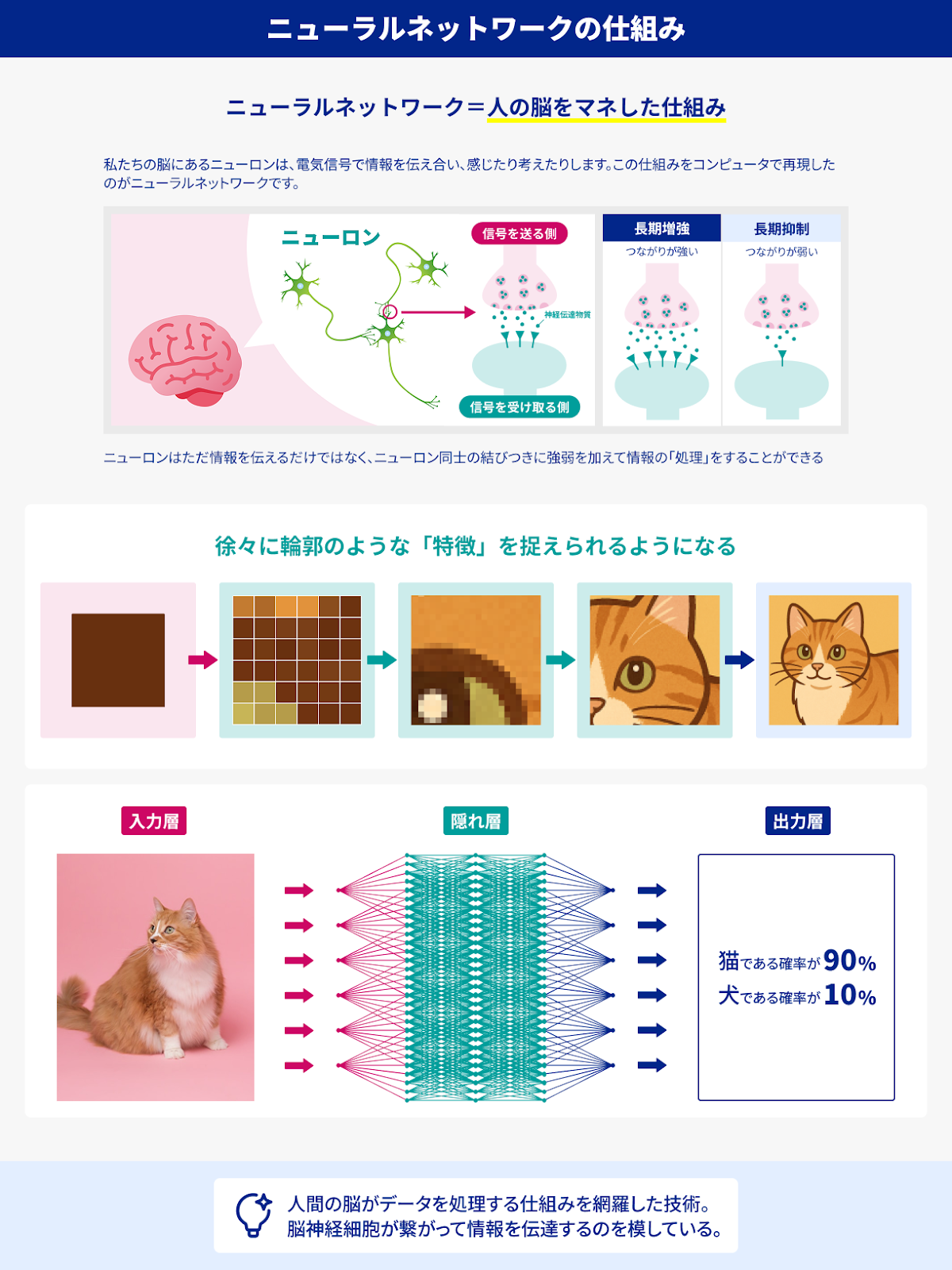
①入力層・隠れ層・出力層
ニューラルネットワークは大まかに、入力層(データを受け取る)、隠れ層(データを変換・抽象化する内部層)、出力層(最終的に結果を出す)の3つに分かれます。
各層には複数のノード(人工ニューロン)があり、ノード同士を結ぶ「重み付きの線」で構成されます。データが層を通過するたびに“重み”による計算と“活性化関数”による非線形変換が行われ、最終的に「犬か猫か」「需要が何個か」というような判断や予測を出します。
②従来は浅い層で限界
かつては、隠れ層が1〜2層程度の“浅い”ネットワークが主流でした。これは、多層化するとパラメータ数が膨大になり、学習に時間がかかり過ぎるうえ、うまく収束せずに性能が安定しないことが多かったからです。さらにデータ自体も大規模に用意しづらい時代だったため、ニューラルネットワークは「潜在能力はあるが扱いにくい」技術とされ、あまり脚光を浴びずに停滞していました。
2-2-2. 深層学習の革命:人間が“特徴量”を設計しなくていい①多層(ディープ)化と膨大なデータ
21世紀に入り、CPU・GPUの性能向上とビッグデータの出現が重なり合うと、ニューラルネットワークをいよいよ多層(深層)化できる環境が整います。いわゆる“ディープラーニング(Deep Learning)”は、隠れ層を10層以上積み重ねるなど“深い”ネットワークを使い、大量のデータを学習させることで、本来の潜在能力を爆発させました。
ここで起きた最も大きな変化が、「人間が特徴量を決める必要が激減した」という点です。従来は、「この画像の色ヒストグラム、輪郭長、形状パラメータ……」など手動で注目点を設計し、モデルに入力する必要がありました。しかし、深層学習では大量の画像をそのまま与えると、下位層が“エッジ”や“角”など単純な特徴を見つけ、中位層がそれを組み合わせた中レベルのパターンを作り、最上位層が最終的に“犬/猫”などの概念を判断する――特徴量抽出がネットワーク内部で自動で完結するようになったのです。
②なぜこれが革命的なのか?
たくさんのデータさえあれば、人間が「どの要素が重要か」を頭をひねらなくても、ネットワークが“最適な特徴”を発見・組み合わせてくれます。「機械がどこに注目すべきかを勝手に学ぶ」という点が、まさにディープラーニングの革命的な要素です。
結果的に、「特徴量設計」という従来の最大のボトルネックから解放され、高度な画像認識・音声認識・自然言語処理などが一気に実用的になりました。

2-2-3. なぜ深層学習は成功したのか?
ディープラーニングが第三次AIブームを引き起こすほど大成功した要因を、もう少し整理してみましょう。
- 圧倒的な計算資源(GPU等)
隠れ層が多いほどパラメータ数が膨大になり、学習には莫大な計算量が必要です。しかし、GPUなどの並列演算が可能なハードウェアが安価に使えるようになり、大規模なネットワークを現実的な時間で学習できるようになりました。 - ビッグデータの登場
インターネットの普及により、画像・テキスト・音声など世界中から莫大なデータが集まりました。層を深くしても十分に学習を回せるほどのデータ量が整備され、データが多いほどネットワークが強力な特徴を学べるという好循環が生まれました。 - シンプルな枠組みを“大規模”に回す強み
ニューラルネットワークの基本アルゴリズム(誤差逆伝播など)は比較的シンプルですが、層を深く、大量のデータで回すと「意外な能力」が発現することがわかりました。人間が「こう考えればいい」と細かく教えなくても、ネットワーク自体が最適化を進める点が従来手法との大きな違いです。
理論編第3章:生成AI(Generative AI)のしくみ
これまでの章で、AIが「大量のデータを学習し、複雑な特徴を自動抽出できる(深層学習)」という技術進化によって第三次AIブームが起きたことを見てきました。
しかし、そのブームは今や「何かを判断・分類する」だけにとどまらず、「何かを新しく生み出す」という領域にまで進んでいます。これが、いま話題の生成AI(Generative AI)です。
たとえば、大規模言語モデルが“文章”を自動で書き下ろしたり、画像生成AIが“存在しない人物写真”や“幻想的な風景”を創り出したり……「え、こんなことまでAIが?」というくらい高い完成度になっています。特に文章・画像の両面でビジネス活用が急拡大し、物販はもちろん、メディア運営や開発業務など幅広い分野が大きな転機を迎えているのです。
本章では、まず「生成AI」とはどんな仕組みを使い、なぜ人間にとって“魔法”のように感じられるほどのクオリティを出せるのかを解説します。その核となる技術のひとつがトランスフォーマー(Transformer)と呼ばれるモデル。特に“Attention”を活用し、大規模データを効率よく学習することで、「単純なタスクを膨大なスケールで回すと意外な能力が発現する」という深層学習の強みが存分に引き出されています。
3-1. トランスフォーマー革命
前章までに、“大量のデータを用いて複雑な特徴を自動抽出する”という深層学習(ディープラーニング)の強みが、第三次AIブームを牽引していることを確認しました。しかし、ディープラーニングの中でも特に画期的な飛躍をもたらしたのが、2017年に公開された「トランスフォーマー(Transformer)」というモデルです。
物販事業における生成AIの導入も、このトランスフォーマーの仕組みをベースにした「大規模言語モデル」や「画像生成モデル」が根幹を支えているといっても過言ではありません。ここでは、トランスフォーマーがどんな仕組みで動き、なぜ“次単語予測”という一見単純なタスクから文章生成や翻訳など多彩な能力を獲得できるのかを見ていきましょう。
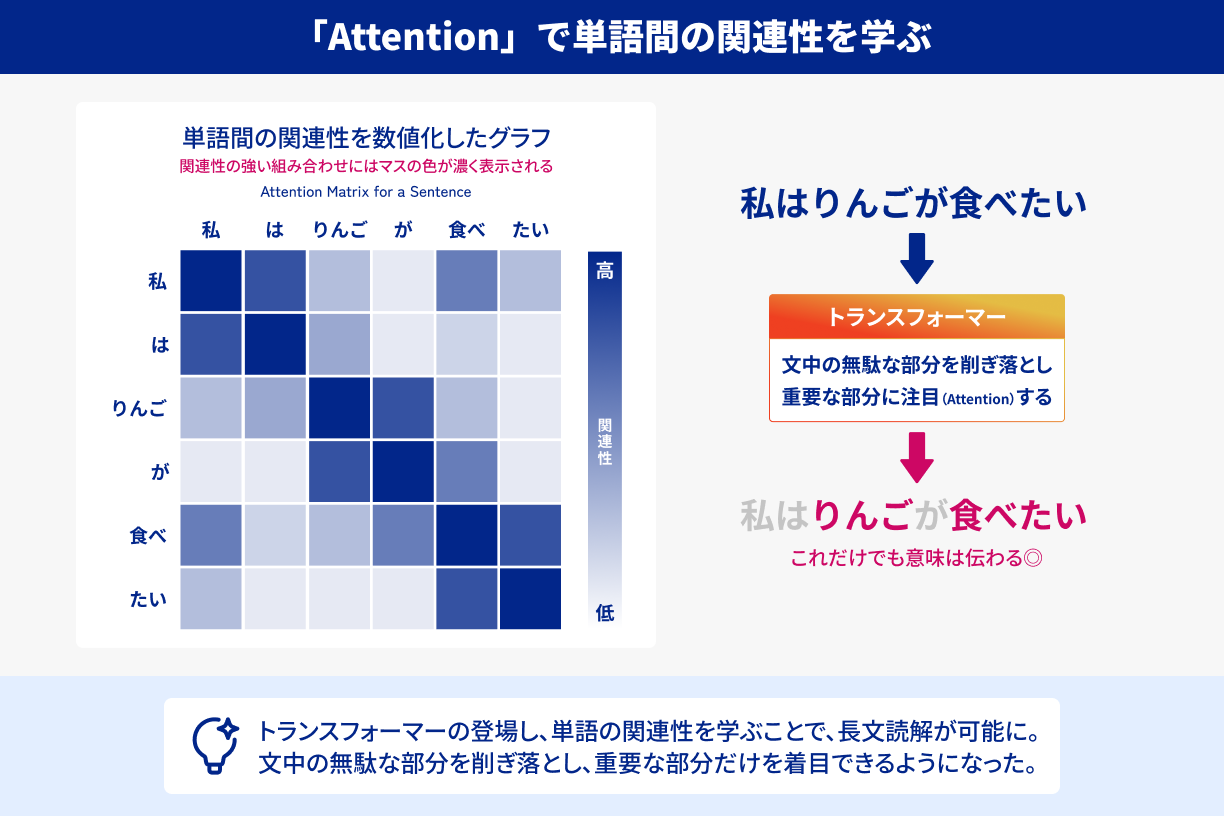
それまでの文章処理は、ある程度の長さの文を「先頭から一単語ずつ」順番に読み込む方式が主流でした。確かに短文なら問題ありませんが、文が長くなるほど処理が膨大になり、学習にも時間がかかり過ぎるという欠点がありました。そこで生まれたのが、“Attention”という概念を核にしたトランスフォーマーです。
この“Attention”では、文章の中で「どの単語がどの単語と強く関連しているか」を一斉にスコア化し、重要度の高い部分に注目を集める仕組みを採用しています。たとえば、
「夕日が沈むころ、薄紫に色づいた雲が水平線を際立たせていた」
という一文を考えると、「夕日」と「薄紫」「雲」と「際立たせていた」などが互いに強いつながりを持ちやすいと判定されます。そうした“関連度の強いペア”に重みを置いて処理するため、文章全体を一気に捉えつつ要点を逃さずに学習できるわけです。
この並列処理の効率の良さにより、数億〜数十億単語という膨大なデータを短期間で回し、モデルが文法・語彙・意味論を深く理解できるようになったのです。
トランスフォーマーを活用した言語モデル――有名どころではChatGPTやBERT(Geminiの前身のLLMモデル)など――の学習タスクは、驚くほどシンプルです。インターネット上の膨大な文章を集め、「文の続きを予測する」というプロセスをひたすら繰り返すだけで、非常に高い言語能力を身につけてしまうのです。
言い換えれば、「大量データ」×「単純タスク」が奇跡のような化学反応を起こしている、ともいえます。これをもう少し具体的に確認してみましょう。
Step 1: 膨大なテキストをかき集める
まずはインターネット上に公開されたニュースサイトやブログ、SNS投稿、書籍のデジタル版など、あらゆるジャンルの文章を集めてきます。データセットの大きさは、数億文を超えることも珍しくありません。「こんなに膨大なテキストを集めて何をするの?」と思うかもしれませんが、すべては“次単語予測”のトレーニングに使われるのです。
Step 2: 一部の単語を隠してみる
集めた文章の一部をマスク(たとえば「今日は友人とカフェに行く(???)」などのように単語を隠す)し、モデルに「ここの単語は何でしょう?」と問いかけます。モデルが誤った単語を予測すれば“誤差”が発生し、その誤差を使ってモデル内部を微調整(誤差逆伝播)するのが深層学習の基本的な流れです。
Step 3: 少しずつ文章を伸ばしながら繰り返す
「今日は 友人と」を見せて次の単語を当てる。その後「今日は 友人と カフェに」を見せて続く単語を当てる……という具合に、文章を段階的に伸ばしつつ同じ作業を繰り返します。何百万回もこのやり取りを行えば、正答率を上げるためにモデルは文脈や単語間の意味、果ては現実世界の常識まで参照しないといけない状態に追い込まれるわけです。
Step 4: 文法・文脈・常識が勝手に育っていく
「今日は 友人と カフェに 行く 予定だ」というフレーズを予測するには、【カフェ】【友人】【予定】といった単語の関係を自然に組み合わせなければなりません。時には「映画」「夕食」「買い物」など選択肢がたくさんあるなかで、文脈的に最も自然な答えを出さないといけない。こうした無数の文章例を読んで次の単語を予測しつづけるうちに、モデルは文法から意味理解まで幅広い能力を身につけます。しかも、人間が「この属性を見ろ」と指定しなくても自力で特徴を捕まえるので、“特徴量を設計しなくていい”という圧倒的なメリットが生まれるわけです。

3-1-3.トランスフォーマーの最大の魅力:並列化とマルチモーダル拡張
トランスフォーマーの仕組みには、「膨大なデータ」を“高速かつ広い文脈”で学習できる並列処理の強みが詰まっています。これは膨大な計算資源(たとえばGPU)との相性が非常に良く、数十億単語規模の訓練でも現実的な期間で実施可能にしました。並列化すればするほど性能が伸びやすく、「次単語予測」だけでも多次元的な言語運用能力が育ってしまう――このスケーラビリティ(規模拡大への適応能力)こそが“トランスフォーマー革命”の核心です。
さらに、テキストだけでなく画像や音声へもAttention機構を応用する動きが進み、“マルチモーダルAI”という新しい時代へ足を踏み入れつつあります。画像生成AIに文章で指示を出して、同時にキャッチコピーや説明文まで生成させる――そんな光景はすでに物販現場や広告制作のシーンで日常化し始めています。
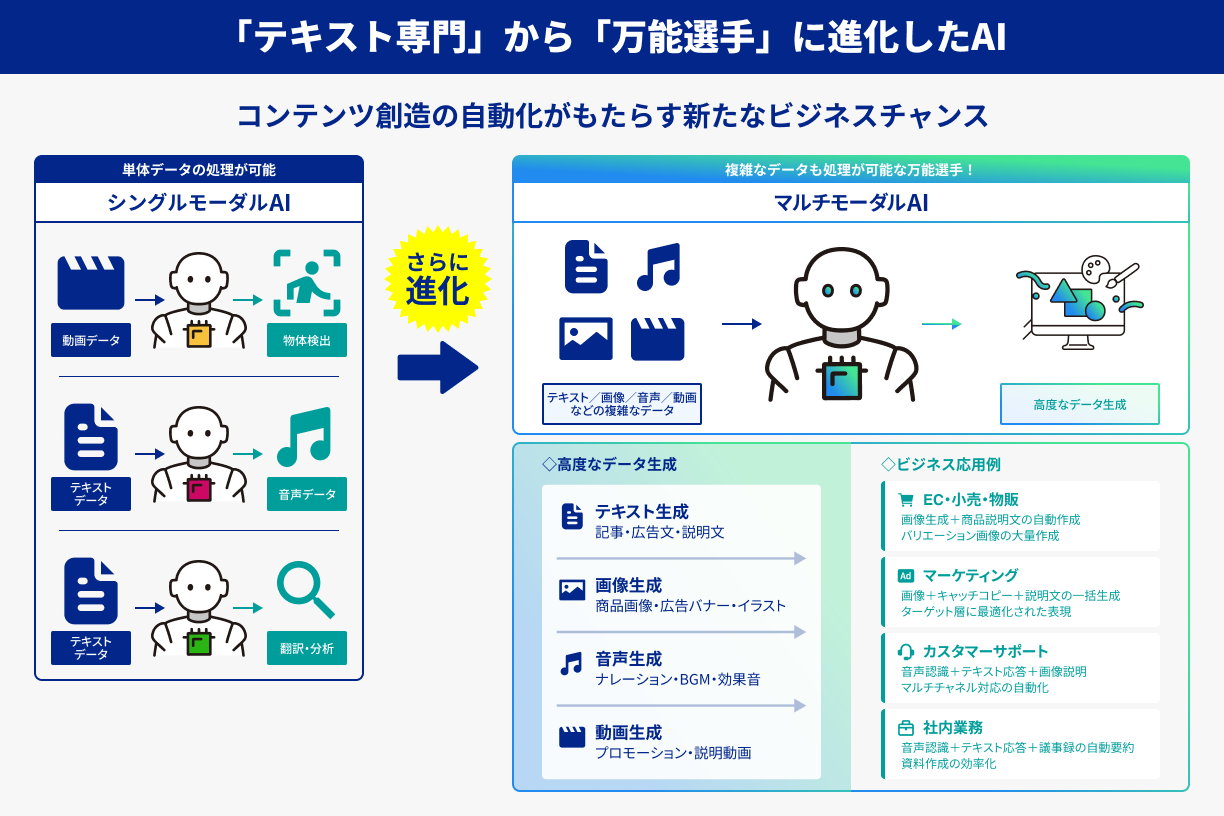
生成AIは、文章や画像、動画、音声までも一貫して“生み出す”プロセスを自動化し、まるでクリエイターのような働きをすることさえあるのです。この仕組みを理解し、“超優秀な新入社員”として賢くマネジメントすれば、あなたのビジネスは圧倒的なスピードでコンテンツを量産し、市場をリードする強力な武器を手にできるでしょう。
3-2. 生成AIがもたらすインパクト
第三次AIブームを加速させた深層学習とトランスフォーマーが結びついた結果、AIは文章や画像、さらには音声や動画までも“生成”できるようになりました。「何かを判断・分類する」段階を超え、「新たなコンテンツを生み出す」という次元に踏み込んだことで、ビジネスやクリエイティブの現場に根本的な変革が起こりつつあります。
3-2-1.自然言語処理から画像・動画生成まで、一気通貫の世界一昔前まで、文章生成と画像生成は全く別の技術領域と考えられることが多かったのですが、トランスフォーマーの“Attention”を応用すれば、単語のような言語データもピクセル情報も「ベクトル表現」として似た仕組みで処理できる可能性が見えてきました。
たとえば、文章生成を得意とする大規模言語モデルが「夏のビーチを背景に、青い服を着たモデルの広告イメージを作って」と指示を受け取り、それを画像生成モデルへ橋渡しし、完成したビジュアルに合わせてキャッチコピーや商品説明文を同時に自動生成する――そうした“マルチモーダル連携”が現実味を帯びています。
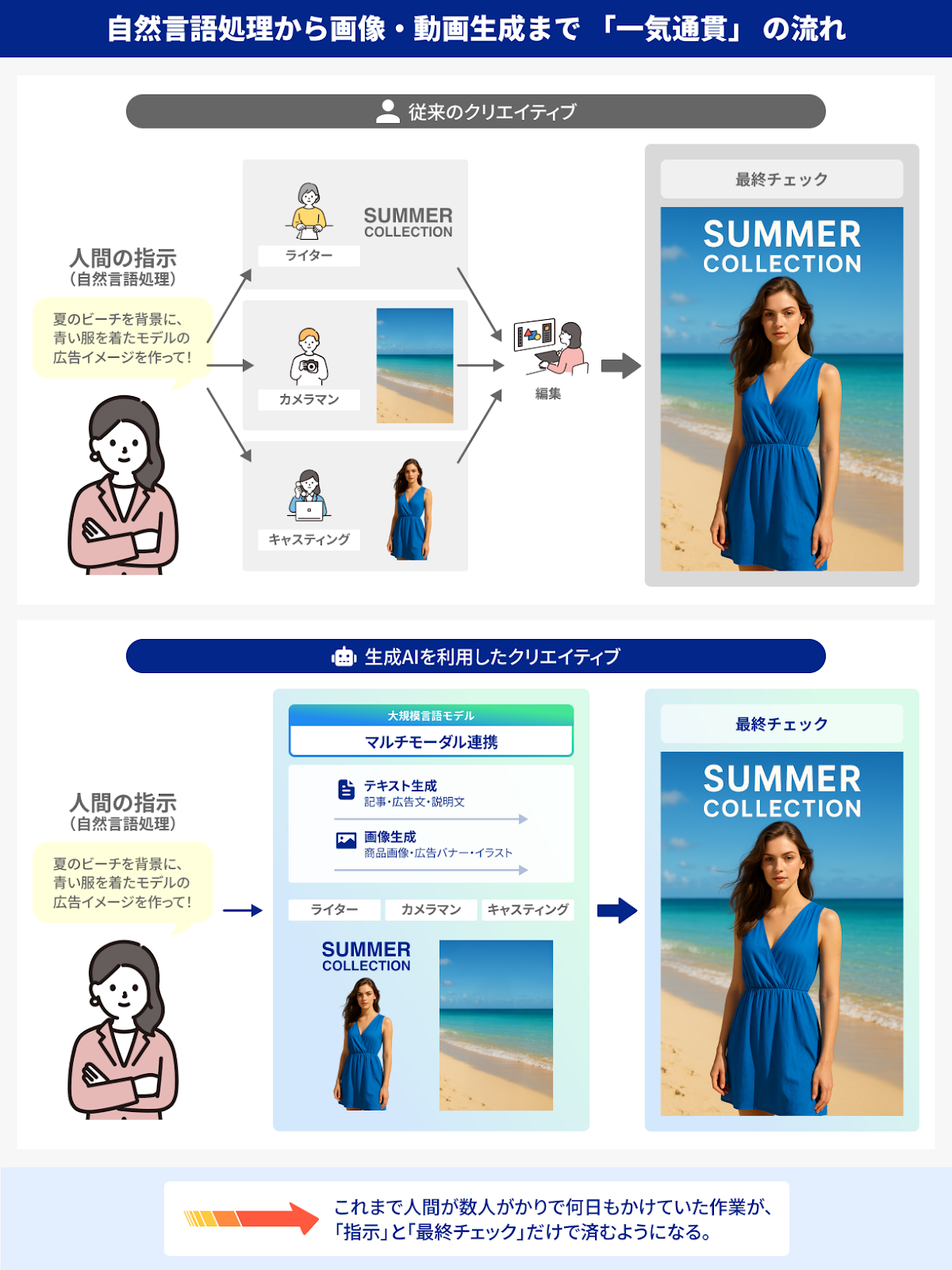
物販事業者の視点で見ると、新商品をリリースするときに「ターゲットは誰か」「どんな世界観で訴求したいのか」を言語モデルへ投げかけるだけで、キャッチコピーからイメージビジュアルに至るまですばやく試作品を量産できる可能性を示しています。これまで数人がかりで何日もかけていた作業が、“指示”と“最終チェック”だけですむようになるかもしれません。
3-2-2.ビジネス実装の急拡大と事例生成AIの普及がここ数年で急拡大している背景には、クラウドサービスやAPIエコシステムの成熟が大きく影響しています。大規模な計算リソースや複雑なモデル構築を自前で行わなくても、月額課金や従量課金の形で簡単に試せる時代になったからです。
海外のECプラットフォームや広告代理店では、商品やサービスをAIが“文章+画像”で多バリエーション生成し、その中から最適なパターンをA/Bテストで見つけるような活用例が増えています。日本国内でも「商品説明を生成AIに書かせて工数を削減」「画像生成AIでSNS広告を短期間で量産」など、ビジネスでの導入が加速しつつあるのが現状です。
物販事業における生成AIの恩恵は、単なる「作業の時短」にとどまらず、品質・創造性・マーケティング効果までを大きく底上げする潜在力があります。
- 商品説明文の自動生成
大規模言語モデルを活用すれば、数十〜数百アイテム分の説明文やキーワードを一括生成し、そこに少し人手で微修正を加えるだけで済むフローを構築できます。作業時間の削減はもちろん、多彩な文体・表現に挑戦しやすい利点もあります。 - 画像生成によるクリエイティブ強化
たとえ実写の撮影環境が乏しくても、AIに「季節感ある背景」「幻想的な光の演出」を指示すれば、見栄えのする合成イメージを低コストで作れます。何通りも試すことで、より訴求力のあるビジュアルを探し出せます。 - 広告コピーやSNS投稿の量産
新作アイテムを毎週リリースする業態では、SNS投稿やメールマガジンの文面が追いつかないという声はよく聞かれますが、生成AIなら「複数パターンのコピーを瞬時に出し、その中から最適案を人間が選ぶ」という運用が可能。リリーススピードを大幅に上げられます。 - リサーチや在庫分析の自動化
生成AIがテキストと対話できるだけでなく、Web検索やAPI連携にも対応していれば、商品や在庫に関する情報整理を自動で済ませる仕組みもあり得ます。価格相場や生産終了品の調査、既存在庫データの更新など、従来は手動でしかできなかった作業の大半をAIに任せられるかもしれません。
いずれのケースでも、“AIに丸投げ”はリスクがあるため、最終チェックや微調整は人間が行うのが前提です。しかし、そこが明確になれば、作業スピードとバリエーションの豊富さは格段に向上するでしょう。
3-2-4.AGI(汎用人工知能)の可能性と現在の距離生成AIがビジネスを席巻し始める中で、しばしば話題に上るのがAGI(Artificial General Intelligence)という概念です。これは「人間と同等、あるいはそれ以上に幅広い領域で思考・学習できる知能」を指し、現在の大規模言語モデルの延長線上でAGIが出現するのではないか、と一部の専門家は予測しています。
ただし、AGIはまだ理論的にも議論が絶えない領域であり、“いつ実現するか”については大きな不確定要素があるのが実情です。実務的には、現在の生成AIは特定のタスクに非常に強い「狭義のAI」として使われるケースが主流であり、「何でもかんでも人間並みに考えられる」わけではありません。そのため、物販やビジネスの現場では「生成AIによる時短や品質向上」をまず狙いつつ、AGIの方向性は将来的なオプションとして注視する――というスタンスが賢明でしょう。
とはいえ、この数年のAI進歩があまりに急速だったため、10年先を見たときにAGIに近い技術が出てくる可能性を“0”とは言えないとも多くの研究者が口にしています。もし、AGI的な能力が部分的にでもモデルへ搭載されれば、物販ビジネスの一連の工程(仕入れ、在庫管理、販売戦略の立案など)さえ「ほぼ自動化」できる未来がやってくるのかもしれません。
AGIへの期待が広がる一方で、現実のビジネスにおいては「いま活かせる技術をどう使うか」が最も重要です。生成AIはまさに“超優秀な新入社員”であり、人間側が与える指示や前提条件が明確であれば、飛躍的なスピードと多様性でアウトプットを生み出すという形で、すでに高い成果を出し始めています。
AGIがどうなるかは将来に委ねつつ、まずはこの「応用範囲がぐんと広がった生成AI」をビジネス現場で最大活用するのが得策でしょう。ここで先行者となった企業は、次に来る技術革新にも柔軟に乗り換えやすい体制作りを進めるはずです。
次の章では、物販事業に特化した“具体的な導入・実装テクニック”を紹介します。生成AIの事例やプロンプト設計のコツを理解すれば、あなたのビジネスでどの工程にAIを組み込めるのかがよりクリアになるでしょう。AGIのような遠い未来を描きつつも、当面は「いま実現できる“時短”と“売上アップ”」という現実的なメリットを掴んでいただきたいと思います。
理論編第4章:AIを使いこなすためのマインドセット
4-1. AIを“超優秀な新入社員”として捉える
4-1-1. なぜ「新入社員」なのか?──超優秀でも“仕事の現場”は初めて生成AIを活用するうえでよくある誤解の一つに、「AIは道具だから、適当に使ってもそれなりの結果が出る」という思い込みがあります。しかし、生成AIの特徴をよく見れば、単なる道具以上に“人間らしい側面”を持っていると気づきます。学習データの量こそ膨大ですが、ビジネス現場の事情は何も知らない。「それなら、どんな存在に近いのか?」とたとえば次のように考えてみると、理解が進みやすくなるでしょう。
あなたは会社で中間管理職として働いています。ある日、新入社員が入社してきました。しかも、東大やハーバード大を首席で卒業したような“超優秀”な新人です。
彼らは幅広い知識を身につけ、あらゆる課題に対して論理的に考える訓練を積んできました。新しいテクノロジーや専門的な理論にも精通しているでしょう。その瞬発力や吸収力は、どの先輩社員にも勝るかもしれません。
しかし、どんなに優秀でも、“あなたの会社の仕事”を深く理解しているわけではありません。業界特有の慣習、取引先や顧客との細かいルール、社内独自の手続き…こうした情報は、入社したばかりでは到底把握しきれないのです。
そんな新人に対して、もしあなたが「適当にやっといて」と指示したらどうなるでしょう?
- 新人は自分なりに最大限の努力をし、あらゆる知識を総動員して取り組もうとします。
- ところが、指示が漠然としていれば「どの方向に進めばいいのか」分からず、膨大な情報の中を迷走するかもしれません。
- 結果として、時間ばかりかかったうえに、求められていないアウトプットが上がってくる…という事態に陥るのは容易に想像できるはずです。
生成AIも、これと同じ状況に陥りがちです。
たとえモデルが数十億単語を学習していても、あなたのビジネスで何が大切なのか、どの顧客層を狙っているのか、どんな制約があるのかなどを明確に伝えなければ、期待する成果にたどり着けません。逆に言えば、前提条件を丁寧に共有できれば、「超優秀な新人」にふさわしい能力を発揮してくれるのです。
特に物販ビジネスでは、ターゲット顧客は誰か? ブランドの世界観はどう伝えたいのか? 検索上位を狙ううえでどんなキーワードが必要か? …こうした情報をちゃんと与えてあげれば、AIは一気に完成度の高い商品説明文や画像を生み出してくれるでしょう。いっぽう、抽象的な要求しか投げかけないと、「え? 何をすればいいんですか?」という状態に陥ってしまい、「AIは使えない」と不満が募る結果になりがちです。
こうして見ると、生成AIを「超優秀な新入社員」として捉えることは非常に合理的です。
知識量は膨大でも、あなたの現場を知らない。だからこそ、優秀な新人が早く戦力になるように、仕事の目的や背景、必要なデータをきちんと説明し、適切なフィードバックを与えることが何よりも大切なのです。
4-1-2. 上司として何を意識すべきか
実際に生成AIを活かすうえで大切なのは、「AIが出した結果が悪いときは、AIではなく指示した側の問題かもしれない」という発想を持つことです。最初から「AIに何でも丸投げすれば勝手に素晴らしい成果を出してくれる」と思い込むと、大抵はうまくいきません。自社製品をどう伝えたいか、何をゴールとするのか、どんな条件や制約があるのか。こうした“前提情報”を逐一教える作業が、本来の上司がやるべき仕事になります。
たとえば、商品説明文をAIに書かせる場合でも、「何文字くらいでまとめるのか」「ターゲットは誰か」「商品の特徴をどう強調したいか」を明確にしないと、ピントのズレた説明しか得られないかもしれません。一方で、細かく要望を伝えれば、AIは驚くほど深い文脈理解を示し、想定外のフレーズや表現をスピーディに提示してくれます。これはまさに“超優秀な部下”に仕事を投げたときのように、「こちらの意図をきちんと汲んでくれるかどうか」にかかっているのです。
また、生成AIのミスや勘違いをそのまま放置せず、人間が必ず最終チェックを行うことも忘れてはなりません。いくら頭の回転が速い新入社員であっても、不慣れな業界特有の用語を間違えたり、他社と比較した調査を省略してしまったりすることがあります。最終的にビジネスに責任を持つのは上司である自分たちなのだ、と意識することで、AIを安全かつ最大限に活かせるようになるでしょう。

こうした「AIは万能ではないが、上司しだいで能力を開花させる存在」という視点が持てると、今後の章で扱う具体的な導入テクニックもより活きてきます。単に最新の技術を追いかけるのではなく、自社のリソースや目標と照らし合わせながら、“人間とAIの協業”をどうデザインするか。そこに、本当に使えるAI活用のカギが隠されているのです。
4-2. プロンプト作成の本質――“いい上司”が出す指示とは
4-2-1. 範囲を明確にする「日本の文化について教えてください」とだけ尋ねても、生成AIは扱う領域があまりにも広大すぎて、どうしても浅く散漫な説明になりがちです。
プロンプト:
日本の文化について教えてください


人間に例えれば「わが社の仕事を一度にぜんぶ覚えろ」と言われるようなもの。どんなに優秀な新人であっても、あまりに膨大なテーマを一度に任されると、力の入れどころを見失ってしまいます。
そこで重要なのが、まず扱う「範囲」をしっかり絞り込むという発想です。大きなテーマをすべてカバーしようとするのではなく、「伝統的な祭り」「茶道」「漫画文化」といった具合に、具体的な要素や切り口をあらかじめ指定しておくわけです。
そうするとAIは「ここだけに集中すればいいんだな」と理解できるため、一歩踏み込んだ説明や事例を提案しやすくなります。たとえば「伝統的な祭りの歴史と、地域経済への影響」というふうに範囲を狭めるだけでも、AIのアウトプットはかなり深みのある内容へ変わっていくはずです。
プロンプト:
日本の文化について、以下の3つの要素(伝統的な祭り、茶道、漫画文化)に焦点を当てて説明してください。




では「範囲を絞る」とはいっても、具体的にどのような例があるのでしょうか。たとえば、以下のような考え方でテーマを限定しておくと、AIにとって「出発点」がハッキリしやすくなります。
たとえば時間的な制限をかけることも一つの方法です。過去5年間に限った市場データを取り上げるとか、江戸時代から昭和初期までの文化的変遷に焦点を当てるとか、そうした時系列の区切りを指定するイメージです。あるいは地理的な範囲にこだわって「東京周辺だけ」「東南アジアだけ」と明示するのも手です。
あるいは、対象を「食品カテゴリーのみ」「男性ユーザーの事例のみ」というふうに狭めるやり方もありますし、単に「A社とB社だけを比較する」パターンでも同様の効果が得られます。「今はコスト削減に関わる要素だけに注目してほしい」「新しいサステナビリティの動きに関連する事柄だけ拾ってほしい」と頼むだけでも、AIがめざす情報の方向性がシャープになります。
ほかにも「成功事例を3つ挙げることに集中してほしい」だとか、製品・ブランド単位で「○○シリーズだけを解説して」と伝えるのも一案でしょう。必要に応じて、技術的視点にこだわるケースなら「スマートフォンのカメラ機能だけを比較して」「このAIツールの翻訳機能だけを評価して」という縛り方ができますし、業種や企業規模に絞り込むやり方も珍しくありません。
大切なのは、あらゆる情報を一気に網羅しようとするのではなく、「まずはここだけを掘り下げて」という指示を明示することです。そのほうがAIとしても限られたテーマに集中し、濃密なアウトプットを生みやすくなりますし、人間の側も「この内容で十分かどうか」をはっきりチェックできます。もし追加の要素が欲しければ、次のステップで「ではもう少し地理範囲を広げて」「さらに競合他社を加えて再度比較して」と依頼すればよいのです。
広範なテーマを一度にすべて扱うと、結局は「ある程度概要をなぞっただけ」で終わってしまいがちですが、焦点を絞ったリサーチや解説はAIが持つ強みを引き出しやすいというメリットがあります。こうした「範囲設定」の巧拙が、まさしく上司であるあなたの腕の見せどころ。範囲を明確にするほど、AIは“超優秀な新人”としての能力をより発揮してくれるのです。
4-2-2. 観点を加える範囲を明確にするだけでも、AIのアウトプットは随分と引き締まりますが、それをさらに深めるには「どんな視点で解説してほしいのか」を指示することが有効です。たとえば「歴史的な観点から語って」と伝えるのか、「海外での評価に着目して」と頼むのかによって、AIが注目する情報の方向性はまるで変わってきます。これは人間に仕事を任せるときと同じで、「同じテーマでも、どこを掘り下げるのか」を上司(人間)が明示してあげないと、結局は一般論に終始してしまいがちだからです。
たとえば同じ「日本の文化」というトピックでも、「社会的影響」を軸にまとめてほしいとオーダーすれば、人々のライフスタイルや地域社会へのインパクト、あるいは世代ごとの受容の違いといった話題が詳しく取り上げられるでしょう。また「経済的な観点」を添えてあげるなら、観光収入や商業施設への波及効果、関連商品の市場規模など、お金の動きを意識した説明が増えるはずです。もし「国際的な視点で見て」とお願いすれば、海外での評価や輸出ビジネスの可能性、あるいは異文化との比較などに重心が移っていくでしょう。
プロンプト:
日本の文化について、以下の3つの要素(伝統的な祭り、茶道、漫画文化)に焦点を当て、それぞれがどのように海外で評価され、影響を及ぼしているかを説明してください。




このように“観点”は、そのまま文章全体の骨格を左右する要素でもあります。別の例でいえば、「技術的・実践的な観点」を求めるなら、たとえば茶道の所作がどのように細かい手順として体系化されているか、あるいは祭りの運営方法がどんな技術で支えられているかに焦点が当たりますし、「若者や次世代への影響」に着目させれば、新しい世代ならではのアレンジやSNS上の盛り上がり、国際的トレンドとの親和性などを深く掘り下げることが期待できます。
もちろん、どの観点で見るのが正解かは、あなたのビジネス目的や読み手のニーズ次第で変わります。海外の顧客に商品をアピールしたい場合には「国際的な評価」や「現地での受容事例」を重視してほしいでしょうし、新規事業のプレゼンを用意するなら、投資家を納得させるために「経済効果」や「市場規模」の数字を意識した観点が必要かもしれません。反対に、ブランドの世界観をアピールしたいときは「美学・芸術的な観点」や「文化保存と継承の視点」がより重要になるかもしれません。
言い換えれば、“観点”は読む人が一番聞きたいポイントを形作る、いわば「レンズ」にあたる要素です。最初の「範囲の明確化」がどのテーマを扱うかを定めるなら、この「観点の指定」は「どういう目線で深堀りするのか」を定めるもの。AIがテーマをじっくり探求するうえで、このレンズを用意してあげるだけで、アウトプットはぐっと実践的で役立つものになるはずです。
4-2-3. 誰に向けて語るのか――“対象(相手)”を明確にする範囲を絞り、観点を定めても、まだ「誰に向けた情報なのか」が曖昧だと、せっかくの内容が宙に浮いてしまうことがあります。たとえば、日本の文化を海外に発信するにしても、「観光庁の職員」なのか「日本文化に興味を持つ外国人旅行者」なのか、それとも「海外の学術研究者」なのかによって、伝えるべきトーンや具体例は大きく変わります。こうした“対象(相手)”の違いは、文章やプレゼンそのものの性格を左右する重要な要素です。
もし「観光や文化プロモーションを行う行政関係者」に向けて説明するなら、政策的な視点や地域活性化の事例を盛り込んだ内容が求められるかもしれません。日本文化の魅力と同時に、その魅力をどう海外旅行客に広めるか、どんな施策を立てれば地域経済に好影響が出るのか――そういった観点が重視されるでしょう。一方で、「日本文化に興味を持つ外国人旅行者」に向けて話すなら、難しい政策論よりも、実際にどこを訪ねて何を体験できるのか、実用的なアクセス情報や見どころが重要になります。
プロンプト:
日本の文化について、以下の3つの要素(伝統的な祭り、茶道、漫画文化)に焦点を当て、それぞれがどのように海外で評価され、影響を及ぼしているかを、観光や文化プロモーションを担当する行政関係者を説明の対象者として説明してください。




また、対象が「海外の学術研究者や専門家」であれば、より専門的な歴史背景や比較文化論など、学問的に深い情報を提示したほうが興味を引けるでしょう。同じ茶道を紹介するにしても、流派の違いや思想的ルーツ、現代のアートシーンとの関係など、学問的におもしろい話題を提供すると喜ばれるはずです。一方、「日本文化をビジネスに活かそうとする企業家」のような相手には、「ビジネス的な可能性」や「市場規模」「収益性」といった要素に力点を置くほうが響きやすいかもしれません。
このように、想定する相手が変われば、テキストの文体や例示も自然に変化します。たとえば親しみやすさを重視するなら、「です・ます調」のフレンドリーな文体にして具体例を多めにするなど、理解のしやすさが優先されるでしょう。逆に、専門家向けなら文体はやや堅くてもよく、データや一次情報へのリンクを充実させたほうが評価が高いかもしれません。結局のところ「対象者にあった言葉選び」こそが、良いコミュニケーションの要なのです。
私たちがAIに指示を出す際も同様で、「誰に向けて説明するのか」をきちんと指定しておけば、AIはその受け手が理解しやすいトーンやレベルを踏まえて文章を組み立ててくれます。たとえば「観光や文化プロモーションを担う行政関係者を対象に、海外での日本文化の評価を解説して」と伝えれば、AIは自然に公的セクターの施策や国際交流の事例などを中心にまとめてくれるでしょう。逆に対象が「日本文化を体験したいと思っている初心者」なら、専門用語の説明を追加したり、文化背景をイチから噛み砕くような書き方をしてくれるはずです。
要するに、範囲(テーマ)と観点(視点)が決まったら、最後に「どの受け手に向けて話すのか」を合わせて指定してあげることで、“超優秀な新入社員”であるAIが、より適切な表現や事例を引き出しやすくなります。ここでのポイントは、「どんな立場の人が、どんな課題や興味を持っているか」を踏まえて、不要な説明を削り、必要な情報にフォーカスさせるということです。そうすれば、読み手にピタリと合ったアウトプットを作り出せるようになるでしょう。
4-2-4. 目的を明確にする範囲を絞り、観点を決め、相手(対象)を特定したら、最後に欠かせないのが「目的」の設定です。どんなに優秀なAIでも、“この仕事で何を実現したいのか”がはっきりしないと、議論や説明がぼやけてしまいます。たとえば、日本文化をテーマにしているとしても、単に「知識を紹介したい」のか、「観光誘致を目的として持続可能な観光モデルを構築したい」のかで、AIが行うべき提案や強調点は大きく変わるからです。
たとえば「日本文化の持続可能な観光モデルを構築する」というゴールを掲げるなら、AIは「環境や地域社会との調和」「文化遺産の保護と体験型プログラムの両立」「収益性と魅力度の両面を考慮した戦略」など、より具体的な施策を意識した説明にシフトするでしょう。そこでは「どんな形で観光客を呼び込み、それが地域活性や文化継承にどう結びつくのか」が最大の焦点となるわけです。
プロンプト:
日本の文化について、以下の3つの要素(伝統的な祭り、茶道、漫画文化)に焦点を当て、それぞれがどのように海外で評価され、影響を及ぼしているかを、観光や文化プロモーションを担当する行政関係者を説明の対象者として、日本文化の持続可能な観光モデルを構築するのを目的にして説明してください。






逆に「外国人観光客を増やすのが目的」という設定であれば、アピールすべきポイントは“簡単かつ魅力的に体験できる要素”や“旅行中の移動アクセス・言語サポート”などになりますし、「日本文化の真髄を深く理解してもらう」のが狙いなら、歴史的背景や精神性への踏み込み、現代社会と伝統の融合事例などが重視されるでしょう。目的が変われば、ゴールに到達するためのプロセスや強調点も変化していくわけです。
また、読む人が目的を共有していれば、AIが提案する施策や解説が“なぜ重要なのか”を理解しやすくなります。たとえば「地域経済を活性化させるため」という目的を明示しておけば、そのゴールに向けて、イベント運営やSNS活用、地元の特産品コラボなど、AIがビジネス的にふさわしいアイデアを優先してくれるかもしれません。一方で、「国際的な文化交流を促進するため」という目的なら、他国での事例やコラボレーションのしかた、翻訳対応の充実などが中心的な話題に上がるはずです。
言い換えれば、「上司(人間)がどんな成果を期待しているか」を明示するのがこのステップのねらいです。目的を具体的に書き込んだプロンプトを用意すれば、AIはそこから逆算して、最適な情報やアイデアを提示しようとします。逆に「目的が分からないまま、とりあえず説明して」と投げかけると、「確かに説明はしているけれど、ビジネス的にはどう活かすの?」という中途半端なアウトプットに終わりがちです。
目的を定めることで、AIの出力は“単なる知識整理”にとどまらず、「目指すゴールに向けて今どんな行動をすればいいのか」を含んだ、具体的かつ実践的な内容になっていきます。そこからさらに細かい施策の検討に進んだり、計画のスケジュールや役割分担を洗い出したりと、仕事の流れ全体が見えやすくなるはずです。これはまさに「なぜこのタスクをやるのか」を理解した部下が、ゴールに向けて能動的に動いてくれるのと同じ原理。AIに仕事を頼むときも、明確な目的を示すことで、そのポテンシャルを最大限に引き出せるのです。
4-2-5. どんな形でアウトプットを受け取りたいのか――“出力形式”を指定する範囲・観点・対象・目的を明確にしたら、最後の仕上げとして「どんな形(形式)でアウトプットを受け取りたいか」を指定すると、AIがより使いやすい成果物を返してくれます。これは、いわば“完成品のフォーマット”を示す行為です。たとえば文章を書くにしても、紙ベースの報告書風、Webページ用のHTML、スライド向けの箇条書き、あるいは動画のシナリオ台本など、様々なスタイルが考えられます。
たとえばブログ記事として公開したいなら、見出し(H2/H3)をしっかりつけたマークダウン形式が便利かもしれません。目次やキーワードリストをあらかじめ挿入させることで、あとからSEO対策がしやすくなるでしょう。もし企画書として上司やクライアントに渡すなら、段落構成が整ったビジネス文書風の出力を望むかもしれませんし、プレゼン資料用であれば要点が端的にまとまった箇条書きの方が助かることもあります。
また、画像生成やデザイン要素を扱いたいなら、「テキスト+画像の配置イメージを提案してほしい」と指定するのも一手です。AIがそのままデザインを完成させるわけではなくても、「ここに見出しを置き、横にイメージ写真を配置」「次にストーリーを段階的に展開する」といったレイアウト案を文字ベースで提案してくれるだけでも、制作時間を大幅に短縮できます。
この“出力形式”の指定は、AIに「最終的にどんな見た目・構成が理想か」を理解させるうえで重要です。具体的には以下のようなバリエーションが考えられます。
- ビジネスレポート形式:
序章・本論・結論という3部構成や、章立て番号を振ったかたちの文章。グラフや表の挿入位置をコメントで示すなど、読み手が「報告書」として受け取りやすくする。 - ブログ記事・Webページ向け:
見出しをH2/H3で指定し、SEOを意識したキーワード配置や、冒頭のリード文を入れるなど、公開時にそのまま使えるスタイルにまとめる。 - プレゼンテーション用スライド想定:
箇条書きを中心にして、1スライド1テーマでまとめる。イラストや写真を置く位置もテキストで示し、視覚的に伝わりやすいストーリーボードを提案する。 - 箇条書き要約 or 長文解説:
すでに分かっている知識をぱっと再確認したいなら短い箇条書きに、じっくり読み物として提供したいなら長文で、というふうにボリュームや文体を調整する。 - HTML・Markdown形式:
ウェブ掲載を見据えているなら、見出しタグやリストタグを埋め込んだ状態で出力させるほうが、コピペ後に修正しやすい。 - プログラムコードとの連携:
もしデータ分析や自動処理を想定しているなら、CSVやJSON形式でのデータ出力を指示するなど、AIに「形式の整ったリスト」を生成させることも可能。
このように、欲しいアウトプットの最終イメージを具体的にAIへ示すだけでも、結果は大きく変わります。あらかじめ想定している活用シーンやメディアに合わせて「どういう文量・構成・スタイル」を希望するのかを明確にしておけば、いちいち手動で再加工する手間を減らせるだけでなく、読み手にとっても格段にわかりやすい仕上がりになるのです。
いわば「この仕事はレポートにまとめてほしいのか、プロモ動画用の原稿にしてほしいのか」という話と同じで、ゴールをイメージしていれば部下(AI)も的確にアウトプットしてくれます。逆に「とりあえず情報整理して」とだけ言うと、AIは形式を推察するしかなく、必ずしも思い通りの成果物にならない可能性が高いでしょう。最終的に使う場面をイメージしながら、「この形式で頼むよ」と伝える――それが“超優秀な新入社員”に確実に成果を出してもらう、最後のひと工夫ともいえるのです。
理論編第5章. AIが苦手な領域と注意点
前節までに、AIを“超優秀な新入社員”と捉え、上司としての指示がいかに重要かを見てきました。しかし、優秀な新人にも苦手分野や注意点があるように、生成AIにも得手不得手があります。ここでは、特に見落としがちな4つのポイントを挙げて解説しましょう。
5-1. 大量タスクを一気に与えると“サボる”生成AIは膨大なデータを処理する能力を持っていますが、「国連加盟国190カ国をすべて1万字で解説してほしい」など、あまりに大規模な作業を一度に丸投げすると、意外なほど“サボり”のような省略現象が起こりやすいです。たとえば冒頭のイントロだけ頑張って書いて、その後は「以下同様」などと小まとめで終わらせてしまったり、「国連加盟国の概略です」とだけ述べて具体的に深堀りしなかったりすることがあります。
一見、「AI=なんでも処理できる」と思われがちですが、実はこの“サボり”は人間の新入社員が「大きすぎる仕事を雑にこなして形だけ報告する」のと同じような理由で起こっています。AIが強みを発揮するためには、一気に大ボリュームを押し付けるのではなく、段階的・小分割的に仕事を与えることが鍵なのです。
5-1-1.なぜ“一気に大量タスク”は失敗しやすいのか
生成AIは膨大な文章を生成すること自体は可能です。とはいえ、大枠のテーマをざっくり指示されただけでは、「どの切り口が大事で、どの情報はそこまで必要ないのか」という優先順位を見極められず、まとめきれなくなります。いわば「1万字で書くとはいえ、どの部分を詳しく書き、どの部分は簡潔に済ませるか」を判断しきれない状態になるわけです。
また、一定の文字数を超えたり、非常に多くのステップを要する場合には、AIが途中で出力を打ち切ることも珍しくありません。これは、メモリや出力制限によって文章を継続できなくなることがあるためです。結局、答えが途中で途切れてしまい、末尾に「以上のようになりますが…」と締めくくるなどして、中途半端に終わってしまうケースも多いのです。
5-1-2.段階的にタスクを与えるメリットこれを回避する最も手っ取り早い方法は、大きな仕事を小さく切り分けて渡すことです。たとえば「1万字で書いて」ではなく、次のように段階を踏んで依頼してみます。
- フェーズ1: まずは全体の構成案を作ってもらう
- 「国連加盟国の項目をどんな区分で整理するか」「各国ごとにどの点を詳しく書くか」など、目次レベルの骨組みを作らせる。
- フェーズ2: 大項目ごとに詳細を生成させる
- 「まずはアジア地域の10カ国について、各国の人口・歴史・文化を500字ずつ書いて」
- これが終わったら「次は欧州地域へ」と順次指示し、出力を積み上げる。
- フェーズ3: 最後に結合・修正
- 各地域ごとの文章を一括でまとめ、AIに仕上げ調整(接続詞の整合・重複記述の省略など)をしてもらう。
- あるいは人間がチェックしてから再度AIに「文体を統一」させてもよい。

このようにフェーズごとに手順を分けてアウトプットを得れば、AIが途中で省略モードに入ったり、唐突に話を終わらせてしまうリスクが減ります。新人に大きな資料作成を頼むときも「まずは目次だけ見せて」「それぞれ1章ずつ完成させて随時レビュー」「最後に全体を統合」などの流れが定石なのと同じ感覚です。
5-1-3.小ステップでのレビューが欠かせない理由段階的なタスク分割をすることで、途中レビューがしやすくなります。AIに任せきりにするのではなく、ステップが終わるごとに「ここまでの文章の方向性は合っているか」「もっと深堀りしたい部分はないか」などを確認することで、修正や追加の要望をこまめにフィードバックできます。
もし最初に大きなタスクを丸投げすると、途中レビューがないまま最終版だけが唐突に出てきて「なんだか論点がずれている」「不要な話題がダラダラ書かれている」となる可能性も高いのです。分割すれば、「ここはもう少し経済面にフォーカスして」「人口動態の数字を細かく入れて」など、段階的に指示を足しやすくなります。
5-1-4.他の使い方にも応用可能「国連加盟国の全解説」という例は分かりやすいですが、実際のビジネスでも、ブログ記事の大量作成や商品の大量リストアップ、あるいは大規模なリサーチなどをAIに一気に任せるケースがあるでしょう。そんなときこそ、小さな単位に切り分けるアプローチを使うと有効です。
- ブログ記事: まず見出しと小見出しを出してもらう → そのあと1見出しずつ書かせて精度を上げる
- 商品リスト: カテゴリーごとに生成を依頼し、出力を一旦チェック → カテゴリーの構成や文言が整ったら次カテゴリーへ
- 集計・分析: 全データを一括処理ではなく、フェーズを区切りにチェックポイントを設置して、間違った分析方向へ進まないよう誘導する
こうした段階管理を行うと、AIが途中で「どうまとめればいいんだろう」と過剰に悩むことを防ぎ、常に適度な塊のタスクで最大パフォーマンスを発揮しやすくなります。
5-2. 批判的視点と新規アイデアは苦手
生成AIの長所を活かすには、それが得意な領域と不得意な領域を正しく把握しておくことが肝心です。中でも見落としがちなのが、“批判的視点”と“まったく新しいアイデア”に対する弱みです。大量の過去データから確率的にもっともらしい文章を組み立てるという仕組みゆえ、逆説や問題点の指摘、既存枠組みを飛び越えるような発想は得意ではありません。
5-2-1.なぜ“批判的視点”が苦手なのかAIは膨大な文書やデータを学習する過程で、多くの場合“ポジティブな関連性”や“肯定的な文脈”をベースにアウトプットを形成します。仮に「このビジネスプランの欠点は何か?」と尋ねても、AIは「こうすればもっとよくなる」という建設的提案に流れがちで、“そもそもこのプラン自体が成り立たない”といった厳しい結論までは踏み込みにくいのです。
そもそも既存の文章群にも、完全な批判・否定ばかりを論じるケースはそれほど多くありません。学習データの傾向が「何かをポジティブに解説する」内容に偏っていると、AIの出力も自然と“肯定的要素を積み上げる”方向へ導かれます。これが、人間のように「ここが論理破綻している」「継続不可能じゃないか」と切り込む力を持つに至らない大きな理由といえます。
5-2-2.既存データ外のアイデアを生み出すことが難しい学習データがベースにある生成AIは、過去に存在した知識・事例を参照しながら“もっともらしいパターン”を導き出す仕組みです。つまり、現実に記録されていない、または非常にマイナーでデータとして見つからない新規性の高いアイデアは引き出しにくいという性質があります。
もちろん“組み合わせ”の幅が広いので、既存の要素同士を混ぜ合わせた面白い提案をすることはあります。しかし、まったく白紙の状態から独創的なプロダクトやビジネスモデルを0→1で生み出すという意味でのイノベーションは、AIに任せてもほとんど起こりません。斬新なアイデアはしばしば、既存の常識や前例とは異なる発想から生まれるため、データに依存するAIには酷な要求だといえます。
5-2-3.具体的なケースのイメージたとえば新規事業の企画会議で、AIに「この事業コンセプトの問題点を全部洗い出して」と命じても、建設的で前向きな意見は多く返ってくるかもしれませんが、真正面から致命的リスクを突いてくる“厳しい指摘”は希少です。人件費の上昇リスクや法的規制の問題などには触れるとしても、「そもそも需要がない」「ビジネスモデルが自己矛盾している」といった抜本的な否定はあまり期待できません。結果として、楽観的なプランばかり膨らんでしまい、会議が外部専門家や実務者によるリアルな突っ込みを欠いたまま進行する恐れがあります。
また、まったく新しい技術の発明や、誰も考えたことがない“逆張りコンセプト”の提案をAIに求めても、大半は既存の類似事例やトレンドを補強した案にとどまることが多いです。過去に蓄積された情報を丁寧に整理する力には長けていても、そこから飛び抜けた“突拍子もないが革命的”なアイデアを生むのはAIには難しいのです。
5-2-4.実践的な対処法- 批判的意見を引き出すには観点を細かく指定
「リスクシナリオを想定し、実行コスト・ユーザー離脱の可能性・競合比較のマイナス要素を洗い出して」と具体的に命じれば、AIもそれに沿った問題点を探す努力をします。完全ではないにせよ、一歩踏み込んだマイナス面の指摘が得られる可能性が高まります。 - ネガティブな事例の分析をあえて学習データとして提示
必要に応じて、「過去に破綻したプロジェクトの概要」をAIに読ませ、そこから教訓を引き出すように誘導します。ポジティブ情報だけでなく、ネガティブ事例を下敷きにすることで、AIの視野が多少は広がり、批判的検討が活性化する場合があります。 - 新規アイデアはあくまで人間主導
ゼロから1を生み出す発想は、人間がブレインストーミングや試行錯誤を行い、AIは「それを裏づけるデータを探す」役割に回すほうが現実的です。求める形は「このコンセプトに近い前例はあるか?」「似た事例の成功・失敗例を出して」というサポート型の利用が有効です。 - 最終審査を人間が必ず行う
批判点が足りないまま「AIが問題ないと言っているし大丈夫」と鵜呑みにするのはリスクが高いです。必ず人間がレーダーチャートを補完する形で「想定外の落とし穴はないか」をチェックする仕組みを導入します。
「批判的視点」や「完全新規の0→1発想」は苦手でも、AIは“広範囲から事例を拾い、複数のパターンにまとめる”といった観点では非常に有能です。よって、アイデア検討の際は「最初の方向性を人間が考える → その方向性をAIに下支えさせる(類似事例調査、成功要因や失敗要因のリストアップ)」といった役割分担がおすすめです。人間の想像力を基点に、AIがサポーターとして働けば、新規ビジネスの全体像がより効率的に洗練されていくでしょう。
5-3. “知ったかぶり”に要注意
生成AIは過去の文章データをもとに非常に自然な言い回しや論理構成を生み出せますが、じつは根拠のない内容をあたかも本当のように語ってしまうことがあるのも事実です。いわゆる“ハルシネーション”や“知ったかぶり”と呼ばれる現象で、誤情報を自信満々に提示したり、実在しない書籍タイトルや人物名をいかにも説得力ある形で挙げたりするケースが見受けられます。人間の新入社員なら「わからないことは上司に確認する」場面であっても、AIは“それっぽい文”を自動生成してカバーしてしまうのです。
5-3-1.なぜ知ったかぶりが起こるのか生成AIは、文字列パターンの確率分布を学習したモデルです。要するに、「この文脈で続くなら、こういうフレーズがもっともらしい」と判断した結果を積み上げています。ところが、現実世界では成り立たない設定や、ソース未確認の数値・引用までも“それっぽい”形で出力してしまうことがあるのです。これは純粋に“次に続きそうな言葉”を算出しているだけで、“その内容が本当に正しいかどうか”を検証していないからこそ起こります。
たとえば歴史上の人物について質問すると、実在しない功績や架空のエピソードをでっち上げる場合があります。あるいは「データの出典は?」と尋ねると、実際には存在しないURLや論文をでっち上げて提示するパターンもあり得ます。人間の目から見ると、そこに確信めいた文体が加わっているせいで、いかにも本物らしく映ってしまいかねません。
5-3-2.ビジネスでのリスク日常的な雑談レベルならともかく、ビジネスの現場では誤情報が大きなトラブルを招く恐れがあります。たとえば商品ページに掲載するスペックが実際と異なっていたり、競合比較の際に根拠のない数値を提示してしまったりすると、信用失墜やクレームにつながりかねません。
また、法務分野や医療分野のように正確性が求められる領域では、AIが示す“それっぽい回答”に依拠したせいで、法的根拠のない主張や、医療根拠のない投薬指示に誘導されるような事態も考えられます。新人社員なら「よくわかりません」と正直に言うところを、AIは“雰囲気”で埋め合わせてしまうので、かえって危険度は増すと言えるでしょう。
5-3-3.具体的な見極めポイント- 出典や参照URLが不明確
結論が書いてあるのに「どこにも原典が示されていない」ときや、提示されたURLを実際に開いても該当情報が見当たらないときは要注意。AIがソースを架空に生成している可能性があります。 - 異様にスムーズな文脈
非常に流麗な言い回しであっても、中身をよく見ると数字や名称が曖昧だったり、具体的に確認しようとすると足りない部分が出てきたりするケースがある。「妙に完璧な流れ」ほど逆に怪しいと思ったほうがいいかもしれません。 - 質問を重ねても情報が深まらない
“知ったかぶり”のままAIが回答を重ねていくと、その答えは矛盾だらけになっていきがちです。突っ込んだ質問をすると「それは機密情報です」などの曖昧な回避回答をしたり、まったく関係のない話題へ飛んでしまうことも珍しくありません。
- クロスチェック
出典を示すようAIに指示し、それらの情報を実際に人間が確かめる。特に数字や日付、人物名などの固有情報が絡む場合は必須作業と考えておく。 - 二次ソースを同時に参照
Google検索や業界の公式データを手動で並行して確認し、AIの回答が妥当か見比べる。AI単独で完結させず、あくまで“検討材料”と位置づけるのが安全。 - 追加の質問で突っ込む
不審な情報があれば「具体的にはどのような実験データがあるのか?」「著者名や出版社は何か?」と立て続けに尋ねる。AIが曖昧な回答を続けるようなら、信頼度は低いと判断する。 - 業務フローに“最終確認”を組み込む
報告書や商品紹介文をAIに生成してもらう場合、人間が必ずチェックリストを通してOKを出す仕組みを用意する。AIの手柄をそのまま鵜呑みにしない。
- 専門的なテーマで深く突っ込んだ質問をしたとき
ディープな専門領域の情報は学習データに偏りがある場合が多く、裏付けが取りづらくなる。その結果、それっぽい文章を整形してしまいやすい。 - 書籍・論文の引用や数値データを尋ねたとき
多くの書籍・論文がAIには断片的にしか取り込まれていなかったり、あるいはそもそも学習範囲外であったりする。タイトルや著者名を“作り”出すことで回答を埋め合わせることもある。 - “要点を箇条書きで100個”のように具体的な数を指定したとき
中身が足りなくても、AIは100個の項目をどうにかひねり出そうとする。根拠の薄い記述や同じ内容の言い換えが並び、実態の伴わないリストが完成してしまう場合もある。
このように「知ったかぶり」の可能性は、AIの処理上どうしても生じがちです。文章がどれほど流暢であっても、その根拠や正確性は常に別途チェックしなければなりません。いわば、新入社員が「大丈夫です!」と太鼓判を押しても、実は裏取りしていない――そんな状況を想定した安全策が求められます。
5-4. AIに“夢を見すぎ”ない
生成AIには目を見張るほどの速度と多様な表現力があるため、一度その威力を実感すると「これで何でもラクに稼げるのでは?」「もう人間の手をほぼ使わずに自動化できるかも」と、大きな期待を抱いてしまうことがあります。しかし、AIはあくまでも“補助的な役割”にとどまる局面が多いのも事実。まるで魔法のようにすべてを自動で処理し、次々と成果や売上を生むというのは現状では難しいでしょう。ここでは、つい抱きがちな「AIへの過度な夢」に対して注意を促す観点を整理します。
5-4-1.自分がまったくできないことをAIに任せても成果は出にくい「ブログや物販で稼いだ経験がないまま、記事生成や在庫管理をAIに丸投げすれば成果につながるのでは?」と考えるケースがあります。たとえばブログ運営に関して、SEOの基礎知識や広告収益の仕組みをよく理解していない状態で記事を大量生成しても、結局は検索エンジン上位に表示されにくかったり、サイト設計が不十分だったりして収益化が失敗しがちです。
結局、稼げる仕組み自体の理解や戦略がなければ、どんなに量産可能なツールを用いても売上には直結しません。AIに作らせたコンテンツの“質”が問いかけられたり、販売導線が整っていなかったりと、人間側がカバーするべきノウハウが不可欠だからです。
「AIが勝手に考えてくれるから、自分は何もしなくていい」と思うのは危険です。売上に直結する業務ほど、シビアな顧客ニーズの汲み取りや微妙な在庫調整、取引先との調整など、人間的な判断が多くを占めています。AIが提示する情報やテキストを最大限に活かすには、受け取る人間が“これは正しいか”“今のタイミングで公表して問題ないか”と最終判断するプロセスがほぼ必須と言えます。
全自動を追求するあまり、誤った表現が世に出てしまえばブランドイメージを損なう恐れがありますし、在庫管理がずれて納期遅延や在庫過多に陥るリスクも否定できません。自動化による効率アップを狙うのは悪いことではありませんが、ヒトのチェックポイントをゼロにすることは現実的ではないでしょう。
AIは、すでに世の中にある情報や事例を吸収し、それを再構成して新しいコンテンツを作り出すのが得意です。ただ、ビジネスでは「どんな情報をどう使うか」という戦略部分や、“どのタイミングで何を仕掛けるか”というセンスが非常に重要になります。
たとえば、自社製品の強みを引き出したキャッチコピーを書かせるにしても、その強みが何であるかを的確にAIへ教えるのは人間です。競合との微妙な差異や、自社ブランドの世界観などを把握できているのも人間側でしょう。AIが生み出す文章自体は優秀でも、そこに自社ならではのノウハウを掛け合わせて初めて“売れるコピー”や“顧客の心をつかむ説明文”が完成するわけです。
AIは常に進化していますが、それに夢を見すぎると「今使っているAIが万能で、このままずっと使える」という誤解にもつながります。実際には、サービスのアップデートや方針変更に伴い機能が変わったり、料金モデルが変更されたり、場合によっては使えなくなるAPIが出てきたりもします。
技術革新が激しいからこそ、「このAIがいつまでも安定して使えるわけではない」という前提で、ある程度リスク分散を図ることが賢明です。たとえば複数の生成AIを並行利用したり、自社内に最低限の技術知識を蓄えておくなどして、依存度を下げる方法が考えられます。
本当に成果を挙げるには、やはり人間とAIの役割分担が欠かせません。AIはたしかにレバレッジを生む強力なツールですが、その根底には各人が積み上げてきた業界知識やノウハウ、それを運用していくマネジメント力がセットで求められるのです。AIに対して過剰な幻想を抱くと、「思ったよりうまくいかない」「なんだ、AIは大したことない」と失望するケースが後を絶たないのは、そのギャップを理解できていないことが理由のひとつと言えます。
理論編第6章:さまざまな生成AIとその使い分け
これまでの章では、AIの歴史や機械学習・深層学習の仕組み、そして物販における導入ポイントなどを見てきました。しかし、いざ実務で「どのAIツールを使えばいいのか?」と考えたとき、近年はあまりに多くのサービスが乱立しているため、最初の選択で躓いてしまう方も多いのではないでしょうか。
本章では、この問いに答えるため、単なるツール紹介に留まらず、2025年現在のECビジネスにおける「AIスタック」という概念を提示します。競争優位性を確立するためには、単一のツールに依存するのではなく、市場リサーチ、コンテンツ制作、顧客対応、データ分析といった各業務フローにおいて、最適なAIサービスを戦略的に「積み重ねて」活用することが不可欠です。
このアプローチの背景には、2025年の主要トレンドである「エージェントAI」の台頭があります。これは、複数の特化型AIエージェントが連携し、複雑なタスクを自律的に実行する仕組みです。本章では、この「AIスタック」を構成する各レイヤーを、基盤となる大規模言語モデル(LLM)から始め、画像、動画、音楽といった具体的なコンテンツ生成ツール、さらにはデザインやリサーチといった業務支援ツールへと順を追って解説していきます。
6-1. LLM(大規模言語モデル)
6-1-1. なぜLLMが重要なのかLLM(大規模言語モデル)は、もはや単なる文章生成ツールではありません。2025年現在、マルチモーダル化と高度な推論能力を獲得したLLMは、ECビジネスのあらゆるAIオペレーションを支える「中央処理装置」としての役割を担いつつあります。商品説明文やキャッチコピーの生成、多言語翻訳、顧客対応テンプレートの整備、市場リサーチといった従来の言語処理タスクはもちろんのこと、今後はより高度な戦略的意思決定の支援基盤となるでしょう。本節では、このAIスタックの基盤となる代表的なLLMを4つ取り上げ、その特徴、料金、そしてECビジネスにおける戦略的な使い分けを深掘りします。
6-1-2. ChatGPT (OpenAI):成熟したエコシステムと専門モデルの力
モデルラインナップ
OpenAIのサービスは、単一の「ChatGPT」という名前の裏で、複数の性能・コストが異なるモデル群を使い分ける構造になっています。汎用的なマルチモーダルモデルであるGPT-4oとその廉価版GPT-4o miniが中心的な役割を担い、より複雑な数学やプログラミング、科学的推論が求められるタスクには、高コストながら専門性の高い「推論モデル」であるo1やo3が用意されています 8。このモデルの階層構造を理解することが、コストと性能を最適化する鍵となります。
料金プランとAPI価格
- Free(無料版): 主にGPT-4o miniへの限定的なアクセスを提供します。
- Plus(月額 20ドル): 個人やプロフェッショナル向けの標準プラン。GPT-4oへの優先アクセスと高いメッセージ上限が提供され、本格的なビジネス利用の出発点となります。
- Team(月額 25〜30ドル/ユーザー): 小規模なECチーム向け。Plusの機能に加え、チームでの共同作業スペース、管理コンソール、そして入力データがモデル学習に使用されないというセキュリティ保証が提供されます。
- Pro(月額 200ドル): 高性能を求めるプロフェッショナルや開発者向け。このプランの真価は、o1やo3といった高度な推論モデルへの無制限アクセスと、「Deep Research」のような専門機能の利用にあります。これは単なる文章生成ではなく、深い市場分析や競合調査といった戦略的タスクを想定したものです。
- Enterprise(カスタム価格): 大企業向け。SSO(シングルサインオン)や高度なセキュリティ、無制限のアクセスが提供されます。
- API価格: 自動化を視野に入れる場合、APIのトークン単価が重要になります。コストと性能のバランスが良いGPT-4oは100万トークンあたり入力2.50/出力10.00、高速・廉価なGPT-4o miniは入力0.15/出力0.60と非常に安価です。一方、最高性能のo1は入力15/出力60と高価であり、タスクに応じたモデル選択が不可欠です。
強み・弱み
- 強み:
- 広大なエコシステム: 世界で最も普及しているプラットフォームであり、数多のカスタムGPTs(特定用途向けボット)やサードパーティ製ツールとの連携が可能です。これにより、多様な業務に対応できる「万能ナイフ」のような役割を果たします。
- モデルの専門分化: GPT-4o miniのような高速・低コストモデルと、o1のような高精度・高コストモデルを使い分けることで、業務の性質に応じたコストパフォーマンスの最適化が可能です。例えば、数千点の商品説明文の自動生成はGPT-4o miniで、四半期ごとの詳細な市場分析レポートはo1で、といった使い分けが考えられます。
- 弱み:
- 高コストな最上位モデル: o1やo3-proといった最高性能モデルは、API利用(100万トークンあたり出力$60〜$600)もProプランも非常に高価で、多くの企業にとっては導入のハードルが高いです。
- 個性なき「AI構文」: 生成される文章が「今日の変化の激しい状況において」といった定型的な表現に陥りがちで、独自のブランドボイスを確立するには相当な編集が必要です。この点は、次に紹介するClaudeと比較した場合の明確な弱点です。

モデルラインナップ
GoogleのGeminiファミリーは、高性能なGemini 2.5 Proと、高速・低コストなGemini 2.5 Flashを主力としています。最大の特徴は、テキスト、画像、音声、動画をネイティブに一括処理できるマルチモーダル性能と、最大100万〜200万トークンという他を圧倒するコンテキストウィンドウ(一度に処理できる情報量)です。
料金プランとAPI価格
- Google One AI Pro(月額 19.99ドル): 一般消費者向けのプランで、Google Workspace(ドキュメント、スプレッドシート等)内で高度なGeminiモデルを利用できます。
- Google AI Ultra(月額 249.99ドル): ChatGPT Proに対抗するハイエンドプラン。2.5 Pro Deep Thinkや動画生成モデルVeo 3への限定アクセスなど、最高の機能と利用上限を提供します。
- API価格(Vertex AI / AI Studio): 非常に競争力が高く、特にGemini 2.5 Flashは100万トークンあたり入力0.30/出力2.50と、ECサイトの大量・定型タスクの自動化に最適です。高性能なGemini 2.5 Proも入力1.25/出力10.00と、OpenAIのo1を大幅に下回る価格設定です。
強み・弱み
- 強み:
- 巨大なコンテキストウィンドウ: 一度のプロンプトで商品カタログ全体や大量の顧客レビュー、数時間にわたる動画ファイルなどを読み込める能力は、包括的な市場リサーチやデータ分析において他社の追随を許しません。
- ネイティブなマルチモーダル処理: 商品画像、プロモーション動画、テキスト説明文を同時に解析し、一貫性のあるマーケティングコピーを生成したり、隠れた消費者インサイトを抽出したりすることが可能です。
- エコシステム連携: Google検索、Workspace、Google Cloudとのシームレスな連携は、既にGoogleのエコシステムを導入している企業にとって、業務自動化の強力な武器となります。
- 弱み:
- 複雑な論理推論: ベンチマークによれば、純粋な数学や高度なプログラミングといった論理推論タスクにおいては、依然としてOpenAIの専門モデルoシリーズやDeepSeekに一歩譲る場合があります。
- ブランドボイスの課題: ChatGPTと同様、生成される文章は汎用的であり、独自のブランドパーソナリティを反映させるには追加のチューニングや編集が必要です。

モデルラインナップ
AnthropicのClaudeファミリーは、最高性能のClaude Opus 4、バランス型のClaude Sonnet 4、そして最速・最安のClaude Haiku 3.5で構成されています。全モデルが200Kトークンという長大なコンテキストウィンドウを備えている点が特徴です。
料金プランとAPI価格
- Free(無料版): Webインターフェースから、1日の利用制限付きで利用可能です。
- Pro(月額 20ドル): より高い利用上限と優先アクセスが提供されます。年間契約で月額17ドルに割引されます。
- Max(月額 100ドル〜): Proプランの5倍または20倍の利用上限を選択できる、ヘビーユーザー向けのプランです。
- Team(月額 25〜30ドル/ユーザー): 最低5名から利用可能な共同作業向けプランです。
- API価格: 非常に競争力があり、特にClaude Haiku 3.5は100万トークンあたり入力0.80/出力4.00と極めて安価です。バランスの取れたClaude Sonnet 4も入力3.00/出力15.00で、多くの用途に対応できます。
強み・弱み
- 強み:
- 卓越したブランドボイスと文章品質: 「AIらしさ」が少なく、自然で洗練された文章を生成する能力は広く認められています。これは、ブランドストーリーや高品質な商品説明文、顧客への丁寧なメール文面など、編集の手間をかけずにブランドイメージを伝えたい場合に絶大な威力を発揮します。
- 長文の文書解析: 200Kのコンテキストウィンドウを活かし、PDF形式の市場調査レポートやサプライヤーとの契約書、法務関連文書などを正確に要約・分析する能力に長けています。
- 安全性と信頼性: 「Constitutional AI」という理念に基づき開発されており、不適切、攻撃的、あるいはブランドイメージを損なうような予測不能なコンテンツを生成するリスクが低いです。これは顧客対応など、安全性が最優先される用途において重要な要素です。
- 弱み:
- 限定的なマルチモーダル機能: 画像解析は可能ですが、画像の生成はできません。Geminiのようなネイティブな動画・音声処理能力や、ChatGPTのような統合された画像生成機能は備えていません。
- ネイティブ検索機能の欠如: リアルタイムのWeb検索機能は標準搭載されておらず、API経由(1,000検索あたり$10の追加料金)またはサードパーティツールに依存します。これにより、最新情報の調査はGeminiやPerplexityに比べて手間がかかります。

モデルと特徴
中国のスタートアップが開発したオープンソースモデルDeepSeek-R1は、特にコーディングと数学的推論の分野でトップクラスの性能を示し、一部のベンチマークではクローズドな商用モデルを凌駕しています。
料金と利用形態
- オープンソース: モデルを自社のサーバーやクラウド環境にホスティングして利用できます。これは、機密性の高いデータを外部に出したくない企業や、ベンダーロックインを避けたい企業にとって決定的な利点です。
- API: deepseek-reasonerモデルが100万トークンあたり入力0.55/出力2.19という驚異的な低価格で提供されており、大量の推論タスクを自動化する際のコストパフォーマンスは群を抜いています。
- 強み:
- 圧倒的なコスト効率: API価格が競合他社の数分の一から数十分の一であり、スタートアップや、ロジックベースのタスク(在庫最適化、価格設定アルゴリズムなど)を大規模に自動化したい企業にとって理想的です。
- データ主権(Data Sovereignty): オープンソースモデルを自社でホスティングすることにより、顧客データや経営戦略などの機密情報が社外に出ることがありません。これはプライバシーとセキュリティを重視する企業にとって最大のメリットです。
- 専門分野での卓越性: コーディングや複雑な論理タスクにおける性能は世界最高水準であり、ECサイト向けのカスタムツール開発やバックエンドのスクリプト作成、データ分析モデルの構築に最適です。
- 弱み:
- 地政学的・規制リスク: 中国企業であるため、データプライバシー規制(API利用時)、国際的な制裁、あるいは特定国からのアクセス制限といった潜在的リスクが伴います。これはグローバルなECビジネスにとって、慎重に検討すべき重要事項です。
- 汎用性と多言語対応: クリエイティブな文章生成や幅広い多言語対応能力については、三大LLM(OpenAI, Google, Anthropic)に比べて実績が少なく、周辺ツールのエコシステムもまだ発展途上です。
2025年現在、単一のLLMですべての業務を賄うという考え方は時代遅れです。市場は「どのLLMが一番か」という問いから、「どのタスクにどのLLMが最適か」という問いへと移行しています。競争力のあるEC事業者は、複数のLLMを戦略的に「スタッキング(積み重ねる)」するアプローチを採用すべきです。
これは、各LLMが持つ明確かつ防御可能な優位性を認識することから始まります。OpenAIは広大なエコシステムとモデルの専門分化、Googleはエコシステム連携と巨大コンテキスト、Anthropicは文章品質と安全性、そしてDeepSeekはコスト、推論能力、オープンソースという独自の強みを持っています。
例えば、あるEC事業者の理想的なAIスタックは次のようになるかもしれません。
- 顧客向けコンテンツ制作: ブランドイメージに直結する商品説明文やメールマガジンは、自然で洗練された文章を生成するClaudeのAPIを利用する。
- 市場・競合リサーチ: 数百ページに及ぶ競合の年次報告書や、数千件の顧客レビュー動画を分析する際は、巨大なコンテキストウィンドウとマルチモーダル能力を持つGeminiを活用する。
- 社内業務の効率化: 日常的な質疑応答や簡単な文章の下書き、多種多様なタスクには、豊富なカスタムGPTsが揃うChatGPTのPlus/Teamプランを利用する。
- バックエンドの自動化: 機密性の高い販売データを用いた在庫最適化アルゴリズムや、動的な価格設定モデルを構築する際は、データ主権を確保でき、かつ論理推論に優れたDeepSeekのオープンソースモデルを自社サーバーで運用する。
このスタッキング戦略を支えるもう一つの重要な視点が、APIのコストパフォーマンスです。モデル間の価格差はもはや僅差ではなく、10倍以上の開きがあります。例えば、100万トークンの出力を生成する場合、OpenAIのo1では60かかるのに対し、DeepSeekの‘deepseek−reasoner‘ではわずか2.19です。これは、APIの選択が単なる技術的判断ではなく、事業の収益性に直結する経営判断であることを意味します。したがって、各自動化ワークフローに対して「このタスクの品質基準を満たす、最も安価なモデルは何か」というコスト便益分析を行うことが、これからのEC運営における新たな必須業務となるでしょう。
6-2. 画像生成AI
EC物販では商品画像やバナー、SNS向けのビジュアル作成が欠かせません。AIであれば撮影コストやデザイン外注費を大きく抑えられる可能性があるため、「まずは画像生成AIを取り入れてみたい」という企業も多いでしょう。ここでは代表的な4種類の画像生成サービスを挙げ、その特徴・料金・強みと弱みを整理します。
6-2-1. Midjourney
概要・特徴
Discord上で動作する有名な画像生成AI。芸術性の高い作風やフォトリアル系まで幅広くカバーし、細部まで緻密な描写が得られると人気です。バージョンアップが継続されており、2025年現在はV7がデフォルトモデルとなっています。V7ではテクスチャの豊かさや、人体(特に手)の描写の一貫性がさらに向上しました。また、静止画から短い動画を生成する機能も追加されています。
料金・利用形態
無料体験は基本的に停止されており、有料のサブスクリプションプランのみが提供されています。
- Basicプラン(月額 10ドル): 約3.3時間/月の高速生成が可能(約200枚相当)。
- Standardプラン(月額 30ドル): 15時間/月の高速生成に加え、無制限の低速生成(Relax Mode)が利用可能になります。
- Proプラン(月額 60ドル): 生成した画像が非公開になる「Stealth Mode」が利用可能。高速生成時間も30時間に増加します。
- Megaプラン(月額 120ドル): 最上位プラン。60時間/月の高速生成が可能で、大量生成を行うプロ向けです。
商用利用と著作権
全ての有料プランで生成画像の商用利用が許可されています。ただし、年間総収入が100万ドルを超える企業は、ProまたはMegaプランの契約が必須です。重要な注意点として、ユーザーは生成されたアセット(画像)を所有しますが、多くの国の法制度ではAIが生成した著作物には著作権が認められていません。これは、生成した画像が実質的にパブリックドメイン(公有)扱いとなり、他者による利用を防げないリスクがあることを意味します。独自のブランドロゴなど、排他的な権利を確保したい用途には不向きです。
強み・弱み
- 強み:
- 圧倒的な品質: 光や質感の表現が秀逸で、アーティスティックで高級感のある仕上がりが得られます。ファッションやインテリアなど、ブランドの「世界観」を表現するのに最適です。
- 幅広い作風: コミック風からリアルな写真まで、多様なスタイル指示に対応できます。
- 巨大なコミュニティ: 他のユーザーが作成したプロンプトを参考にできるため、スキルアップしやすい環境です。
- 弱み:
- Discordへの依存: 企業でのチーム利用には、Discordの運用ルールを整備する手間がかかります。
- 著作権のリスク: 生成物が著作権で保護されないため、ユニークなブランドアセットの作成にはリスクが伴います。

概要・特徴
OpenAIがChatGPTと統合して提供する画像生成AI。最大の特徴は、ChatGPTとの対話を通じてプロンプトを洗練させられる点と、画像内に比較的正確な文字を描写できる能力です。
料金・利用形態
主にChatGPTの有料プラン(Plus, Team, Proなど)を通じて利用します。月額20ドルのPlusプランでも、常識的な範囲で無制限に生成可能です。また、Microsoft DesignerやCopilot経由で無料(クレジット制)で利用することもできます。API経由での利用も可能で、1枚あたり$0.04〜$0.12程度の従量課金制です。
商用利用と著作権
OpenAIの利用規約では、ユーザーが生成した画像を所有し、再販や商品化を含む商用目的で自由に使用できると定められています。これはMidjourneyに比べてシンプルで分かりやすいライセンス体系ですが、AI生成物全般の著作権不受理という根本的な法的課題は同様に残ります。
強み・弱み
- 強み:
- テキスト描写能力: 「50% OFF」のような文字を含む広告バナーやキャンペーン画像をAIだけで完結させられる点は、他のツールに対する明確な優位性です。
- ChatGPTとの連携: テキスト生成から画像生成までをシームレスに行えるため、非デザイナーでも扱いやすいワークフローを構築できます。
- 導入の手軽さ: 普段使っているChatGPTのインターフェース内で完結するため、追加のツール導入が不要です。
- 弱み:
- 画風の偏り: 生成される画像がやや「AI風」の合成的な見た目になりがちで、Midjourneyのような芸術性や質感を求める用途には不向きです。
- カスタマイズ性の低さ: オープンソースではないため、モデルの独自チューニングなどはできません。

概要・特徴
Stability AIが公開したオープンソースの画像生成モデル。最新版はStable Diffusion 3で、新しいMMDiTアーキテクチャによりプロンプトへの忠実度や文字描写能力が向上しています。最大の特徴は、誰でもモデルをダウンロードしてローカル環境で実行できる点と、LoRAなどの拡張機能を用いて特定の画風やキャラクターに特化させられる無限のカスタマイズ性です。
料金・利用形態
- ローカル実行(無料): モデルのソースコードをダウンロードし、自社のPCやサーバーのGPUで実行する場合、ライセンス料はかかりません(ハードウェア費用は別途必要)。
- クラウドサービス/API: Stability AI自身もAPIを提供しており、サードパーティ製のWebサービス(DreamStudioなど)も多数存在します。
商用利用と著作権
2024年7月にライセンスが改定され、新しい「Community License」が導入されました。これにより、年間総収入が100万ドル未満の個人および企業は、Stable Diffusion 3を含むモデルを無料で商用利用できるようになりました。これを超える規模の企業は、別途Enterpriseライセンスの契約が必要です。ユーザーは生成したアウトプットを所有し、自由に使用できます。
強み・弱み
- 強み:
- 自由度と拡張性: オープンソースであるため、自社の商品カタログでモデルをファインチューニングし、一貫性のある商品画像を生成するなど、独自のカスタマイズが可能です。
- コスト効率: 大量の画像を生成する場合でも、ローカル環境で運用すれば追加のライセンス費用がかからないため、トータルコストを大幅に抑制できます。
- 活発なコミュニティ: GitHubやCivitaiなどのプラットフォームに、無数のカスタムモデルやプラグイン、ノウハウが共有されており、学習リソースが豊富です。
- 弱み:
- 導入のハードル: セットアップにはPythonや関連ライブラリの知識が必要で、非エンジニアにとっては敷居が高いです。
- 自己責任での運用: トラブルが発生した場合、基本的には自力で解決する必要があります。
- 品質のばらつき: ベースモデルの品質は必ずしも最高ではなく、高品質な結果を得るには、適切なカスタムモデル(チェックポイント)やLoRAを選択・適用するノウハウが求められます。

概要・特徴
GoogleがAI Test Kitchen内で実験的に公開している、ユーザビリティに特化した画像生成ツール。基盤技術にはGoogleの最新モデルImagen 3が使われています。プロンプトを入力すると、AIが「こういう修飾語はどうですか?」といった形で関連キーワード(Expressive Chips)を提案し、ユーザーはそれをクリック操作で試しながら理想の画像に近づけていくことができます。
料金・利用形態
現在はベータ版として、米国、ニュージーランド、ケニア、オーストラリアなど一部の国でアカウントを持つユーザーに無料で提供されています。一般公開後の正式な料金プランは未定ですが、将来的には有料化される可能性が高いです。
強み・弱み
- 強み:
- 直感的なUI: AIがプロンプト作成を支援してくれるため、初心者でも試行錯誤しながら高品質な画像を生成しやすいです。
- 高い写実性: Imagen 3モデルにより、フォトリアルな画像の品質が高いと評価されています。
- 手軽さ: 無料で利用でき、Webブラウザだけで完結します。
- 弱み:
- ベータ版の制約: 現在は利用できる地域が限定されており、機能も不安定な場合があります。
- 機能の限定: 当初は正方形の画像しか生成できないなど、他のツールに比べて機能が制限されている部分があります。ビジネスレベルでの安定性や機能性は、今後の正式リリースを待つ必要があります。
ECビジネスにおける画像生成AIの選択は、「何を作りたいか(目的)」と「誰がどのように運用するか(体制)」という二つの軸で考えるべきです。
一つの考え方は、「アートディレクターのツール」と「マーケティング制作のツール」を区別することです。
- Midjourneyは、ブランドの「世界観」や「雰囲気」を創り出すアートディレクターのツールです。高級感のあるライフスタイル写真や、抽象的な背景画像を生成するのに最適ですが、具体的なテキスト入りの広告バナーには不向きです。
- 4o Image GenerationやStable Diffusionは、より具体的なマーケティング制作ツールです。4o Image Generationはテキスト入りのバナー広告など、特定の指示に基づいた素材を素早く作るのに長けています。Stable Diffusionは、自社製品でファインチューニングすることで、一貫性のある商品画像を大量に、かつ低コストで生産する究極のインハウスツールとなり得ます。
もう一つの重要な判断基準は、商用ライセンスと著作権リスクです。
- Midjourneyや4o Image Generationの生成物は、規約上は商用利用可能ですが、著作権保護の対象外となる可能性が高く、ユニークなロゴやブランドキャラクターの作成には法務的なリスクが伴います。
- Stable Diffusionは、年間収益100万ドル未満の企業であれば無料で商用利用できる新しいライセンスを導入し、スタートアップや中小企業にとって非常に魅力的な選択肢となりました。
これらの点を踏まえ、以下のマトリクスは、EC担当者が日々の業務で直面する具体的なタスクに対して、どのツールが最適かを判断するための一助となるでしょう。
6-3. 動画生成AI
静止画を超えて“動き”を自動生成する動画生成AIは、ここ数年で急速に進化しているものの、2025年現在、実務利用においてはまだ多くの課題が残っています。テキストプロンプトだけで長尺の動画を破綻なく生成するのは依然として難しく、多くの現場では「まず高品質な静止画を生成し、それを短いクリップに変換する」という二段階のアプローチが主流です。
したがって、現在の主な用途は、SNS広告や商品紹介ページに埋め込む数秒から十数秒程度のショート動画制作に限定されるのが現実的です。本節では、代表的な7つのサービスを取り上げ、それぞれの特徴とECビジネスにおける使いどころを評価します。
6-3-1. Sora (OpenAI)
概要・特徴
OpenAIが提供する動画生成モデル。当初、そのデモ映像の品質で大きな話題を呼びましたが、実際の利用はChatGPTのProプラン(月額200ドル)加入者に限定されており、さらに生成には追加クレジットが必要となる高コストなサービスです。
使いどころ・評価
最大20秒程度の動画を生成できますが、ユーザーからは「プロンプトを無視して意図しない映像になる」「動きの品質が低く、破綻やノイズが多い」といった報告が相次いでいます。特に人物やアニメ調のキャラクターの動きは苦手とされ、現状ではチャットUIからシームレスに試せるという点以外に実用的なメリットは乏しいと言わざるを得ません。OpenAIというブランド力による期待値は高かったものの、高額なコストに見合う品質には達しておらず、本格的な業務利用には不向きです。
6-3-2. Hailuo AI
概要・特徴
短尺のキャラクターアニメーションや、バーチャルヒューマンが話すような映像制作に特化したツールです。比較的自然な表情や口の動きを生成できるため、簡単なプレゼンテーションや商品説明動画に適しています。
料金・利用形態
- フリープラン: 1日3本まで、透かし付きで生成可能。
- 有料プラン(月額 29ドル〜): 透かしの除去、優先的な生成、より長い動画の作成が可能です。
使いどころ・評価
10秒前後のアバタートーク動画であれば実用レベルに達しており、導入のハードルは低いです。企業紹介や商品説明でキャラクターに語らせるようなコンテンツを手軽に作成したい場合には有効な選択肢となります。しかし、それ以上の長さになると一貫性が失われやすく、また、複雑なデザイン(例:和服など)は崩れやすい傾向があります。
6-3-3. KLING
概要・特徴
最大2分という、他のツールに比べて長尺の動画生成に対応可能な先進的ツール。特にリアルな風景や実写風の人物描写に重点を置いており、1080pの高解像度出力もサポートしています。
料金・利用形態
- 無料プラン: 1日66クレジットが付与され、無料で試せますが、生成キューが混雑していると数時間から半日程度の待ち時間が発生することがあります。
- Standardプラン(月額 10ドル): 660クレジット/月が付与され、透かしが除去されます。
- Proプラン(月額 37ドル): 3000クレジット/月が付与され、優先キューでの高速生成が可能になります。
- Premierプラン(月額 92ドル): 8000クレジット/月が付与され、ヘビーユーザー向けです。
使いどころ・評価
光の表現や背景の奥行き感が自然で、リアルな映像品質を求める場合には最も有力な選択肢の一つです。しかし、無料プランでは生成の失敗が頻発し、また、意図通りの結果を得るためのプロンプト作成には習熟が必要です。本格的なプロモーション映像の制作ポテンシャルは秘めているものの、そのための学習コストと運用コスト(有料プラン契約)を考慮する必要があります。
6-3-4. Vidu
概要・特徴
アニメ風キャラクターのショート動画(8〜15秒)を素早く作れるAIツール。
彩度やコントラストを自動補正する仕組みがあり、ビビッドなアニメ調の映像が得られやすいです。
細かい動きより、キャラ登場やテキスト演出を派手に見せる用途に向いています。
料金・利用形態
- 無料プラン:月20本まで・各8秒程度
- 有料:月9.99ドル〜で、最大30秒程度のクリップを生成できる
使いどころ・評価
手軽さは魅力で、SNS投稿向けのポップな動画づくりには重宝します。ただ、15秒を超えると破綻率が上がり、連結作業が前提になります。
アニメ独特の動きを再現するには、複数回に分けた生成&編集が必要なので、本格アニメ制作というよりは短いCMや告知動画程度がベター。
彩度が強めに出るため、カラフルな演出が欲しいシーンには合う反面、落ち着いたリアル系を作りたい場合は不向きです。
6-3-5. Luma Dream Machine
概要・特徴
静止画をアップロードし、それに動きやカメラワークを加えて5〜10秒程度の短い動画を生成する機能に定評があります。特に光や照明効果の表現がドラマチックで、TikTokやInstagramリール向けの「映える」映像制作に強みを発揮します。
料金・利用形態
- 無料プラン: 月に30本程度の動画生成が可能です。
- Liteプラン(月額 9.99ドル): 3200クレジット/月が付与され、720pの動画を生成できます。
- Plusプラン(月額 29.99ドル): 10,000クレジット/月が付与され、HD画質での出力が可能です。
使いどころ・評価
SNS広告用のインパクトある短いクリップや、ECサイトのトップページで静止画に動きをつけたい場合など、小回りの利くツールとして非常に有効です。Lumaの強みは、リアルな物理法則に基づいた動きの再現性にあり、他のツールよりも自然なモーションが得られやすいと評価されています。一方で、複雑な人物の動作や長尺の物語を生成することは想定されておらず、あくまで「静止画+短い動き+演出」の範囲に特化しています。
6-3-6. Runway
概要・特徴
動画生成だけでなく、編集、エフェクト合成、字幕追加など、映像制作に関連する機能をワンストップで提供するクラウドプラットフォームです。「Gen-3」といったモデルを用いてテキストや画像から動画を生成できますが、その真価は生成後の編集工程までを同じUIでシームレスに行える点にあります。
料金・利用形態
- 無料枠: 125クレジットが付与されます。
- Standardプラン(月額 15ドル): 625クレジット/月が付与され、透かしが除去されます。
- Proプラン(月額 35ドル): 2250クレジット/月が付与され、より長い動画の生成が可能です。
- Unlimitedプラン(月額 95ドル): クレジットが無制限になります。
使いどころ・評価
動画生成機能単体の品質で言えば、KLINGやLumaの方が優れている場面もあります。しかし、Runwayは「動画制作のワークフロー全体を効率化する」という点で独自の価値を提供します。例えば、他のAIで生成した複数のクリップをRunwayにインポートし、カット編集、テロップ追加、エフェクト合成を行って一本の動画として完成させる、といった使い方が現実的です。動画生成から編集までを一つのツールで完結させたい場合に最適な選択肢です。
6-3-7. Pika Labs
概要・特徴
テキストや画像から短い動画を生成するプラットフォーム。3Dアニメーション、シネマティック、アニメ、カートゥーンなど多様なスタイルに対応し、リップシンク機能も備えています。また、「Scene Ingredients」機能により、背景やキャラクターを個別にカスタマイズできるなど、クリエイティブな制御が可能です。
料金・利用形態
- Basicプラン(無料): 月に150クレジットが付与されますが、商用利用はできません。
- Standardプラン(月額 10ドル): 700クレジット/月が付与されますが、こちらも商用利用は不可です。
- Proプラン(月額 35ドル): 2000〜2300クレジット/月が付与され、商用利用が可能になり、透かしも除去されます。
- Fancyプラン(月額 95ドル): 6000クレジット/月が付与され、最速の生成速度とすべての機能が利用できます。
使いどころ・評価
SNS向けのショート動画やマーケティング用の広告映像を手軽に作成するのに適しています。特に、リップシンクやシーンの要素を細かく制御できる機能は、eコマースの商品デモ動画などで役立ちます。ただし、無料プランやStandardプランでは商用利用ができないため、ビジネスで活用するにはProプラン以上への加入が必須です。
6-3-8. まとめ――短尺クリップの利用が中心、長尺はまだ試験段階2025年現在、動画生成AIの実務利用は、SNS広告や商品紹介向けの5〜15秒程度の短いインパクト映像の制作が中心です。テキストプロンプトだけで長尺動画を高品質に生成するのは依然として困難であり、「静止画AIでキーとなるフレームを精緻に作り込み、それを動画AIで短く動かす」という二段階のワークフローが最も現実的かつ効果的です。
- Sora: OpenAIブランドへの期待とは裏腹に、高コストでありながら品質が低く、現状では実務利用のメリットはほとんどありません。
- KLING: リアルな風景や実写風の動画で、最大2分までの生成に対応しており、品質を最優先するなら最もポテンシャルの高いツールです。
- Hailuo / Vidu: アニメ調やキャラクター主体のコンテンツを手軽に作りたい場合に適しています。
- Luma Dream Machine: 静止画にドラマチックな動きと光の演出を加え、SNS向けの短いクリップを制作するのに最適です。
- Runway: 動画の生成から編集までをワンストップで行える総合プラットフォームであり、制作ワークフロー全体の効率化に貢献します。
- Pika Labs: リップシンクやシーン制御など、クリエイティブな機能が豊富で、SNSや広告向けの動画制作に強みがあります。
今後、KLINGのようなツールがモデルのアップデートを重ねることで、より安定して長尺の本格的な映像を生成できるようになる可能性はありますが、現時点ではまだ試行錯誤の段階にあると考えるべきでしょう。
6-4. 音楽生成AI
物販事業で商品をアピールする際、短尺CMやSNS動画、あるいはECサイトや店頭用の“待機音”などでBGMを流したいシーンは意外と多いものです。従来は「ロイヤリティフリーの音源サイトを探す」「作曲家に外注する」といった方法が一般的でしたが、近年は音楽生成AIを活用することで、オリジナルのBGMを短時間かつ低コストで作れるようになりました。
ただし、動画生成AIと同様に、音楽生成AIもまだ発展途上の側面があり、「狙った曲調が出にくい」「ボーカル入り楽曲は難度が高い」などの制約が残っています。それでも、商品PVやSNS広告に使う短めのBGM、サイト演出用のループ音源などを作るには十分実用レベルに達しています。本節では、代表的な4つのサービス(Soundraw / Suno AI / Stable Audio / AIVA)と、注目度が高まっている2サービス(Udio / Mubert)について比較し、それぞれの特徴・料金・使いどころを整理します。
6-4-1. Soundraw
概要・特徴
日本発の音楽生成サービス。ジャンル、ムード、テンポなどを選ぶだけで、AIがインスト曲を自動作曲します。Webブラウザ完結型で、曲の長さや構成(イントロ・サビなど)をある程度カスタマイズできる点が特徴です。近年はArtistプランも追加され、生成した音源にユーザーがボーカルを乗せて音楽配信サービスでリリースすることも可能になりました。
料金・利用形態・商用利用
- フリープラン: 無料で試用できますが、非商用利用に限られます。
- Creatorプラン(月額 19.99ドル): 商用利用が可能になり、無制限にダウンロードできます。YouTube動画や広告、ゲームなどのBGMとして幅広く使用できます。
- Artistプラン(月額 39.99ドル〜): Creatorプランの権利に加え、生成した音源のステムデータ(各楽器パートの音源)をダウンロードし、ボーカルを重ねてSpotifyなどで配信・収益化できます。著作権はSoundrawと共有する形になります。
- API利用: 企業向けにAPIが提供されており、自社アプリやWebサービスにBGM自動生成機能を組み込むことが可能です。
使いどころ・評価
操作が非常に簡単で、日本語UIにも対応しているため、初心者でも手軽に利用できます。ECのPR動画やSNS広告、YouTubeの背景BGMなど、「短めのインスト音源」が欲しいシーンに最適です。著作権トラブルのリスクが低いロイヤリティフリー音源を、自社のイメージに合わせて安価に量産できる点が最大の強みです。
6-4-2. Suno AI
概要・特徴
テキストで指示するだけで、ボーカル入りの楽曲を生成できる先進的なサービス。歌詞、曲調、ボーカルスタイルを指定すると、AIが30秒〜1分程度のクリップを生成します。これを複数回「Extend(延長)」機能で繋ぎ合わせることで、数分尺の楽曲を作成する仕組みです。
料金・利用形態・商用利用
- 無料プラン: 1日に10曲程度まで生成可能ですが、非商用利用に限定されます。
- Pro/Premierプラン: 有料プランに加入すると、生成回数が増え、商用利用が可能になります。
- 著作権に関する注意: Suno AIは現在、大手レコード会社から著作権侵害で提訴されています。AIの学習データに許諾なく既存の楽曲が使用されたと主張されており、法的な先行きは不透明です。そのため、有料プランで得られる「商用利用権」も、将来的にその有効性が揺らぐリスクがあります。特に、生成された楽曲が既存のアーティストの作風に酷似している場合、トラブルに発展する可能性も否定できません。
使いどころ・評価
短いジングルやSNS広告向けのキャッチーな歌モノを素早く作りたい場合に便利です。歌詞とメロディ、ボーカルまで一括で生成できる手軽さは革新的です。しかし、前述の著作権訴訟のリスクを考慮すると、現時点での本格的な商業利用は慎重になるべきです。特にブランドの公式な広告や、長期的に使用するコンテンツへの採用は避けた方が賢明でしょう。
6-4-3. Stable Audio
概要・特徴
画像生成AI「Stable Diffusion」で知られるStability AIが開発した音楽生成AI。
テキストプロンプト+秒数指定で短いインスト音源を生成する仕組み。主に30〜90秒程度のBGMや効果音向け。
「Stable Audio 2.0」では最大3分程度の楽曲構成も作成可能となり、企業利用や広告案件への展開が進んでいる。
料金・利用形態
- 無料プラン:月20トラックまで生成可(非商用利用)。1曲45秒上限。
- Proプラン:月額12ドル前後。高音質WAVや最大90秒〜3分の長尺生成が可能で、商用利用も許可。
- エンタープライズ契約:大規模配信(TV/映画など)やアプリ内実装、月数千〜数万曲規模の大量生成も対応。
- API利用:Stability AIのプラットフォームで従量課金モデルを選択可能。
使いどころ・評価
- 使いどころ:短尺BGMや効果音を作るのが得意。インディーゲームや広告用ジングルにも最適。
- 強み:音質が高く、ランダム生成でも比較的クオリティが安定。著作権リスクが少なく企業も導入しやすい。
- 弱み:曲の展開やメロディラインが単調になりやすい。歌入り曲は非対応。

概要・特徴
2016年から開発が続く“AI作曲家”で、クラシックや映画音楽風の壮大なBGM生成を得意とする。
楽譜やMIDIを出力でき、他ソフトウェアでの編集やアレンジが容易。
ポップスやロック系も作れるが、主力ジャンルはオーケストラやピアノ重視の重厚サウンド。
料金・利用形態
- 無料トライアル:月3曲ダウンロード可(非商用)。
- Standardプラン(月15ユーロ程度〜):SNS等での収益化OK。ただし、YouTube広告以外の商用利用は制限あり。
- Proプラン(月49ユーロ程度〜):作曲権をユーザー側が保持し、映像作品やゲーム、広告など幅広い商用利用が可能。
- エンタープライズ契約:API連携や大量楽曲生成に対応。個別見積もり。
使いどころ・評価
- 使いどころ:壮大な映画トレーラー風やクラシカルなBGM。ゲームや映像の劇伴に強い。
- 強み:楽譜やMIDIを出力できるので、他のDAWでさらに作り込みやすい。Proならユーザーが著作権を取得可能。
- 弱み:無料枠が少なく、プランによって商用利用範囲が大きく異なる。ロックやEDMなどビート系はやや苦手。

概要・特徴
2024年に公開された新興サービス。ボーカル入りの楽曲を生成でき、歌声の自然さが高いと評判。
テキストプロンプトで「こんな歌詞・ジャンル・展開」と指示すると、AIが数十秒単位で歌+伴奏を自動生成。
現在β版のため無料で月数百曲生成でき、商用利用も可能。ただしクレジット表記が推奨されている。
料金・利用形態
β版無料:月600曲ほど生成可能。商用利用OK(“Generated with Udio”などのクレジット推奨)。
将来的に有料サブスク導入予定。インペインティング(曲部分差し替え)などの高度機能が追加される見込み。
エンタープライズプラン:企業利用やゲーム実装、カスタマイズモデルを要望する場合は個別相談。
著作権に関する注意
UdioもSunoと同様に、大手レコード会社から著作権侵害で提訴されています。ベータ版であるため利用規約が将来変更される可能性も高く、生成された楽曲の独占的な使用権は保証されません。Sunoと同様、本格的な商業利用にはリスクが伴います。
使いどころ・評価
- 使いどころ:広告曲やSNS向けの歌ものデモ、仮歌を高速で試作したい場面。
- 強み:AIボーカルの表現力が高く、英語圏中心ながら歌心を感じさせるクオリティ。
- 弱み:β版ゆえ不安定で、楽曲の独占使用は不可。将来的にプランが変更される可能性あり。Sunoと同様の法的リスクを抱えています。
概要・特徴
ムード・ジャンル・BPMを指定すると、ループ可能な電子音楽や環境音BGMをリアルタイム生成。
長時間にわたり無限ループ再生できるため、店舗BGMやライブ配信、イベント会場での常時BGM用途に好相性。
API連携でアプリ内に組み込み、ユーザー操作に応じて動的にBGMを変化させる活用事例が増加中。
料金・利用形態
- 無料プラン(Ambassador):個人・SNS向けの限定的利用。トラックを独立リリースは不可。
- Creatorプラン(月14ドル程度):SNS収益化動画やNFT作品などのBGM使用可。
- Pro / Business:企業広告、TV/ラジオCM、アプリ内BGMなど広い商用利用範囲をカバー。月39ドル〜数百ドル規模。
- API利用:アプリ・サービスへの組み込み可。大規模商用は個別契約。
使いどころ・評価
- 使いどころ:無限ループBGMを必要とする配信、イベント、店舗など。SNS動画のBGM量産にも向いている。
- 強み:即時生成でエンドレス再生でき、著作権処理が明確。企業プランでは店舗などへの大規模導入も可能。
- 弱み:ボーカル曲には対応していない。ループ曲が中心なので展開が単調になりがち。
音楽生成AIは、ECの商品PVやSNS広告向けのBGMをスピーディに用意する上で、非常に強力なツールとなっています。
- 安全なインスト曲を求めるなら: SoundrawやStable Audioが第一候補です。操作が簡単で、著作権リスクも低く、企業が安心して導入できます。特にSoundrawはAPI連携により大量生成にも対応可能です。
- 壮大な楽曲や著作権の完全保持を求めるなら: AIVAのProプランが最適です。MIDI出力による高度な編集も可能で、ブランド独自の楽曲制作に適しています。
- 店舗や配信で長時間利用するなら: 無限ループBGMを生成できるMubertが唯一無二の選択肢です。ライセンス体系が明確で、商業施設での利用にも対応しています。
- ボーカル入り楽曲を試すなら(要注意): Suno AIやUdioは革新的な技術ですが、大手レコード会社との著作権訴訟という重大なリスクを抱えています。現時点では、本格的な商業利用、特にブランドの根幹に関わるようなコンテンツへの使用は推奨できません。デモ制作やアイデア出しといった内部利用に留めるのが賢明です。
いずれのサービスを利用する場合でも、プランごとに商用利用の範囲やライセンス条件が大きく異なるため、公式サイトで最新の規約を必ず確認することが不可欠です。「広告CMでの使用可否」「楽曲の単体配信は可能か」「API連携はどのプランで提供されるか」といった細かな条件を比較検討し、自社の目的とリスク許容度に合ったサービスを選びましょう。
6-5. 音声生成AI (音声合成・TTS)
昨今、動画コンテンツやSNS広告、カスタマーサポートの自動応答、多言語展開に向けたガイド音声など、音声合成(TTS: Text-to-Speech)技術を活用する機会が急増しています。従来は「機械的なロボット声」か「プロの声優・ナレーターを雇う」以外の選択肢が限られていましたが、近年のAIの進化により、人間らしい自然な抑揚や感情表現を備えた高品質TTSを手軽に導入できるようになりました。
本節では、以下7つの代表的な音声生成AIについて、最新機能・料金・利用形態・商用利用、そして筆者が感じた評価を解説します。
- ElevenLabs
- Amazon Polly
- Google Cloud Text-to-Speech
- CoeFont
- PlayHT
- Murf.ai
- Microsoft Azure TTS

概要・最新機能
「AI音声クローン」分野で大きく注目を集めるサービス。英語を中心に多言語に対応し、短時間の録音から高精度な声の複製が可能。感情表現が極めて豊かな“ニューラル音声合成”が強みで、長文ナレーションやキャラクターボイス制作にも向いています。WebエディタやAPIで手軽に利用でき、2024年にはリアルタイム会話向けモードも導入し、低レイテンシー化を推進中です。
料金・利用形態・商用利用
- 無料プラン: 月1万クレジットまで合成可能ですが、商用利用は不可で、帰属表示が必要です。
- Starterプラン(月額 5ドル〜): 月3万クレジットまで合成でき、商用利用が解禁されます。自分の声をクローンする「Instant Voice Cloning」も利用可能です。
- Creatorプラン(月額 22ドル〜): 月10万クレジットまで利用でき、より高品質な「Professional Voice Cloning」や高音質オーディオ(192 kbps)が利用可能になります。
- Pro以上のプラン: さらに大規模な利用を想定したプランで、44.1kHz PCMの高音質出力などにも対応します。
評価と使いどころ
ElevenLabsは、特に英語コンテンツにおける「感情表現の豊かさ」で最高峰の品質を誇ります。ナレーションやオーディオブックなど、聞き手の感情に訴えかけるコンテンツ制作には比類ない強みを発揮します。音声クローン機能も手軽で高品質です。一方で、日本語のイントネーションはまだ発展途上であり、国内向けコンテンツでは不自然さが残る場合があります。英語圏向けの高品質な音声が最優先であれば、ElevenLabsが最良の選択肢となるでしょう。
6-5-2. Amazon Polly
概要・最新機能
AWSのクラウドTTS。標準音声とニューラル音声(NTTS)を提供し、安定的・大規模な運用が可能。
Generative Voiceや長文読上げ用プレミアム音声も追加され、AWSサービスとの親和性が高い。
料金・利用形態・商用利用
- 従量課金制:標準4/100万文字、ニューラル16/100万文字。長文のNTTSは$30~$100/100万文字など。
- 無料枠:新規AWSアカウントで12か月間、標準500万文字・NTTS100万文字/月が無償。
- 商用利用:AWS利用規約の範囲内で追加ライセンス不要。大量合成はエンタープライズ契約も選択肢。
評価と使い所
Amazon Pollyは大規模利用に最適です。すでにAWSインフラを使っているなら導入のしやすさとコスト管理の明快さが強み。標準音声はやや古めかしい部分もありますが、ニューラル音声(NTTS)は十分自然です。感情豊かというよりは「安定・無難」という印象なので、派手な表現を求める映像制作には物足りないかもしれません。それでも月何百万文字というスケールで回すならポリ一択、というくらいローコストで運用しやすいです。
6-5-3. Google Cloud Text-to-Speech
概要・最新機能
GoogleのWaveNet技術を核に、多言語対応と高い音声品質を兼備したクラウドTTS。
Neural2音声やStudio音声などが追加され、音質や抑揚がより自然になっている。90言語以上に対応。
料金・利用形態・商用利用
- 従量課金:標準4/100万文字、WaveNet/Neural216/100万文字、Studioは$160/100万文字。
- 無料枠:毎月標準400万文字、WaveNet/Neural2 100万文字まで無償で試せる。
- 商用利用:Google Cloudの利用規約に従えばOK。無料枠があるので小規模なら実質コスト0で運用可能。
評価と使い所
Google TTSは多言語展開が視野にあるなら最強です。WaveNetの自然さはトップクラスで、英語や主要言語では非常に聞き取りやすい声が手に入ります。何より毎月の無料枠が大きいので、小~中規模プロジェクトなら費用がほぼかからない点が魅力。ただしUIは開発者向けで、ドキュメント読んでAPIを叩く前提なので、ノンエンジニアにはとっつきにくい。技術的には優秀ですが、華やかな表現力を重視する映像制作よりは、汎用的な読み上げ的な使い方が主になる印象です。
6-5-4. CoeFont
概要・最新機能
日本発のTTSサービスで、特に日本語の自然なイントネーションに定評があります。50文程度の短い録音で自分の声をAI化する機能が人気で、野沢雅子さんなど有名声優を含む1万種類以上の公開ライブラリから音声を選べます。リアルタイムで声を変えるボイスチェンジャーや、会議のリアルタイム翻訳を行うCoeFont Interpreterといった機能も提供しています。
料金・利用形態・商用利用
- 無料プラン: 一部の音声が利用可能ですが、商用利用にはクレジット表記が必要です。
- Standardプラン(月額 20ドル): 約8万文字/月まで生成可能。商用利用が解禁され、クレジット表記も不要になります。
- Plusプラン(月額 350ドル): 100万文字/月まで生成可能。API連携や法人向けの管理機能(最大5ユーザー)が提供されます。
評価
CoeFontは日本語コンテンツの制作においては、最も自然で高品質な音声を提供します。国内向けの動画ナレーションやオーディオ広告、キャラクターボイスなど、日本語の繊細なニュアンスが求められるあらゆる場面で最適です。海外言語には弱いですが、「日本語の自然さ」を最優先するなら、CoeFontが唯一無二の選択肢となります。
6-5-5. PlayHT
概要・最新機能
Webブラウザだけで使えるAI音声ジェネレーター。60言語以上対応で、数百種のリアル音声を提供。
「Ultra Realistic Voices」や簡易クローン機能など高品質路線。英語に特に強い。
料金・利用形態・商用利用
- 無料プラン:月2,500〜5,000ワードまで試用可(商用不可or透かし入り)。
- Pro($39〜$99/月) / Premium:商用利用権が付与され、月数十万~無制限文字プランも存在。
- API / Enterprise:大量生成やホワイトラベル利用などにも応じる。個別見積もり。
評価
PlayHTは英語圏向けコンテンツをまとめて大量生成したいときに便利です。数百種の声が「ありそうでなかった音色」をカバーしており、コード不要で簡単操作できるUIも優秀。その分料金はやや高めだと思います。日本語の選択肢が少ない点は微妙で、日本語音声を本格的に作りたい場合には不向き。英語圏メイン、あるいは短期で大量ナレーションを作成して一気に動画を量産する場面なら候補になるでしょう。
6-5-6. Murf.ai
概要・最新機能
120以上のAI音声と20言語をカバーし、動画編集+BGM挿入+音声合成をワンストップで行えるTTSサービス。
ブラウザの専用スタジオでテキスト入力→ナレーション生成→BGM統合を直感的に操作可。
APIや企業向けカスタム音声も提供し、eラーニングや広告動画制作の導入事例が増加中。
料金・利用形態・商用利用
- 無料プラン:月10分まで合成可能(ダウンロード不可)。
- Basicプラン($19/月〜):年24時間分の音声生成枠、60種音声・10言語に対応。商用利用OK。
- Proプラン($26/月〜):全音声120種を解放、AIボイスチェンジャーなど高度機能追加。
- Enterprise:5ユーザー〜無制限利用可能。APIや音声クローンは個別契約。
- 商用利用:基本プラン以上は商用ライセンス付属。生成音声を自由に二次利用可。
評価
Murf.aiは「映像制作の生産性アップ」に最適なサービスです。テキストとBGM、複数音声を一つの画面で編集できるので、動画編集初心者でもサクッとナレーション付きコンテンツを量産できるのは非常に便利です。英語音声の自然さもElevenLabsに匹敵するレベル。ただし本格的な音声クローンは社内依頼が必要で、手軽さではElevenLabsに劣ります。月10分しか無料で試せないのも敷居が高めで、短期利用だと割高感があるかもしれません。
6-5-7. Microsoft Azure TTS
概要・最新機能
Microsoft Azureの音声合成サービス。140以上の言語・方言に対応し、500種超のニューラル音声を提供。
SSMLで感情やスタイルを細かく指定可能。カスタムニューラル音声で企業専用キャラボイスも作れる。
大規模負荷にも耐えるクラウド基盤で、ゲームやコールセンターなどエンタープライズ採用事例多数。
料金・利用形態・商用利用
- 従量課金:100万文字で約16(バイト数ベース)、利用量増えるとディスカウント。無料クレジット:初回登録時に200付与。規模が小さいと月50万文字程度は実質無料との報告も。
- Custom Neural Voice:別途契約が必要、企業専用の大規模録音データでブランド音声を生成。
- 商用利用:Azure全体の利用規約に準拠。大規模企業のAPI導入でコールセンター自動応答や読み上げソリューションが進んでいる。
評価
Azure TTSは世界規模のアプリやサービス向けに最良の選択肢です。140言語を超える対応と500種以上の声バリエーションは圧倒的ですし、感情表現も細かく調整可能。すでにAzureを利用している企業なら導入のハードルが低いし、十分な予算があればCustom Neural Voiceで独自キャラクター音声を作るのも魅力です。反面、個人クリエイターやノンエンジニア向けには敷居が高く、ドキュメントを読んでAPIやPortalを操作する必要があります。表現の華やかさはElevenLabsに負けるシーンもあるので、要件次第でしょう。
6-5-8. まとめ――TTSサービスの選び方AI音声合成サービスは急速に進化し、それぞれが得意分野、料金体系、UIスタイルを異にしています。自社の目的を明確にし、最適なツールを選択することが重要です。
- コストと文字数: 大量生成なら従量課金制(Amazon Polly, Google TTS, Azure TTS)、定額で使いたいならサブスクリプション制(ElevenLabs, CoeFont, Murf.ai)が基本です。特にGoogle TTSは無料枠が非常に大きいため、小規模利用なら最有力です。
- 対応言語と感情表現:
- 英語の感情表現を最重視するならElevenLabs。
- 日本語の自然さを最優先するならCoeFont。
- グローバルな多言語対応が必要ならGoogle TTSまたはAzure TTS。
- 開発者向けかクリエイター向けか: APIを駆使してシステムに組み込みたいならAWS/Google/Azure。直感的なUIで手軽にコンテンツを作りたいならElevenLabs/CoeFont/Murf.ai。
- 音声クローン: 自分の声や特定のキャラクターの声を複製したいなら、手軽なElevenLabsやCoeFontが便利です。
- 動画制作との連携: 音声合成から動画編集まで一気通貫で行いたいならMurf.aiが生産性を高めます。
ECビジネスにおいて、動画広告の訴求力向上、カスタマーサポートの効率化、グローバル展開など、AI TTSの導入メリットは計り知れません。上記の比較を参考に、自社の目的、予算、技術リソースに最適なサービスを検討し、ビジネス効果を最大化してください。
6-6. デザインAI
物販ビジネスでは、商品の良さを伝えるための「画像づくり」や「資料・プレゼン」など、“デザイン業務”の必要性が高い反面、「毎回外注するのはコストがかかる」「社内デザイナーが手いっぱい」「ちょっとした修正でもすぐに対応しにくい」といった悩みがつきまといます。そこで注目されているのが、デザイン支援AIです。
たとえば既存の画像生成AIを活用する方法もありますが、「チラシやバナーなど複数の要素を配置しなければならない」「情報の優先順位を考慮したレイアウトが必要」といったときには、“総合的なレイアウト”を自動で提案してくれるサービスがあったほうが効率的です。また、プレゼン資料やランディングページを、ほぼテキスト指示だけで自動整形してくれるツールも増えてきました。本節では、代表的なデザインAI(Canva / Gamma / NapkinAIなど)を中心に、最近リリースされた類似ツールや機能アップデートまで含めてご紹介します。
6-6-1. Canva AI
概要・特徴
オンラインデザインツールとして世界的に普及しているCanvaは、近年「Magic Studio」と呼ばれる生成AI機能群を次々に追加しています。テキストプロンプトからデザイン案を生成する「Magic Design」、フォーマットや言語を変換する「Magic Switch」、テキストから画像や動画を生成する「Magic Media」、画像の不要な部分を消去・置換・拡張する「Magic Eraser」「Magic Edit」「Magic Expand」など、多岐にわたる機能でデザイン作業を自動化・効率化します。
料金・利用形態
- 無料版: 基本的なテンプレートやAI機能を試せますが、一部機能は制限されます。
- Pro / Teams(月額 1,500円程度〜): チームでの共同作業機能や高度なブランド管理、AIによる大量デザイン自動作成機能などが利用できます。
使いどころ・評価
ECの商品バナー、SNS用グラフィック、店頭ポスター、LPデザインの構成案など、デザイナーがいないチームでも手早く目を引くビジュアルを作りたい場合に最適です。最大の強みは、AIで生成した要素をそのままCanvaの直感的なエディターで微調整できる点にあります。「AIで下書き→人間が仕上げ」というワークフローが非常にスムーズです。ただし、AIによる画像生成の品質そのものは、Midjourneyのような専門ツールには及びません。
6-6-2. Gamma
概要・特徴
「文章を入力するだけでプレゼン資料が完成する」と話題になったツール。スライドや文書のコンテンツを大まかな文章で書き込むと、AIが自動でレイアウトを整え、関連するアイコンや画像まで配置してくれます。従来のPowerPointのようなスライド形式ではなく、ウェブページのようにスクロールするカード形式のデザインが特徴で、インタラクティブな要素(動画、GIF、投票など)の埋め込みも簡単です。
料金・利用形態
- 無料プラン: 月間の生成数に制限があります。
- Proプラン(月額 10〜30ドル程度): 生成上限が大幅に増え、商用利用が可能になります。ブランドロゴやカラーパレットを登録し、一貫したデザインを生成することもできます。
使いどころ・評価
「商品の特徴をまとめた社内共有資料」や「セールス施策の企画書」など、時間をかけずに見栄えの良い資料を作成したい場合に非常に有効です。PowerPointのような本格的なソフトの操作を習熟せずとも、指示テキストだけで素早くプロフェッショナルな見た目の下書きが完成します。ただし、既存資料の読み込みや編集機能は弱く、またPowerPoint形式へのエクスポートはレイアウトが崩れることがあるため、あくまで新規作成やアイデア出しの段階で強みを発揮するツールです。
6-6-3. NapkinAI
概要・特徴
アイデア整理やユーザーフロー図、思考のマッピングに特化した“AIホワイトボード”ツール。
テキストや画像をドラッグ&ドロップすると、AIが関連項目を紐づけ、インフォグラフィック風の整理図を自動レイアウト。
特にUX設計や思考整理において、付箋のように情報をペタペタ貼っていくと、AIがまとめたマインドマップやチャートを提案してくれる。
料金・利用形態
- 無料プラン:ホワイトボード1〜2個まで、月内で生成制限あり。
- Proプラン($12/月):無制限ボード、チームコラボ機能、商用利用OK。
使いどころ・評価
- 使いどころ:商品コンセプト出しや開発アイデアの発散・収束、競合比較などのリサーチ結果をビジュアル化したいとき。
- 強み:手書きやテキストでアイデアを入力すると、それを自動的にカテゴリー分け&配置してくれるため、情報整理がスピーディ。UIが直感的で、会議でのブレストに重宝。
- 弱み:実際に商用デザインとして仕上げるわけではなく、あくまでアイデア可視化ツール。B2C向けの広告・チラシに使う感じではない点に留意が必要。
概要・特徴
Microsoftが2023年後半に正式リリースした、DALL-E等の画像生成エンジンを統合したオンラインデザインツール。
テキストで「○○用のSNS画像を作って」と指示すると、AIが複数案のバナーや広告素材を提案。文字や配置をドラッグ&ドロップで微調整可能。
Microsoft 365と連携しやすく、OutlookやPowerPointに直接挿入したり、クラウド上でチームと共有できる。
料金・利用形態
一部無料。Microsoft 365加入者は追加機能解放、プレビュー中のGenerative機能も使える。
今後、月数ドル程度の有料プランに移行する可能性あり(公式アナウンス次第)。
使いどころ・評価
- 使いどころ:SNSの告知画像や広告バナー、社内報デザイン、簡単な資料の挿絵など、Windowsユーザーが導入しやすい。
- 強み:UIがシンプル、Office系と連携。画像生成AIを使った素材の生成→文字入れ→最終レイアウトまで一貫して行える。
- 弱み:AI画像の品質はまだMidjourney等には及ばない。商用利用のライセンス条件も今後変更の可能性あり。

概要・特徴
UIデザインに特化した生成AIツール。テキスト指示で「こういう画面構成にしたい」と書くと、それをもとに編集可能なUIモックアップを作成。
Figmaのようなデザインソフトと連携し、生成したUIをコンポーネントとして取り込める(Sketch/Adobe XDとも部分連携あり)。
プログラミング不要でプロトタイプができるため、スタートアップのアイデア検証やサービスUI提案に活用され始めている。
料金・利用形態
Beta版(招待制):一部無料枠あり。 有料プラン:月額$30程度〜。生成回数やAPI利用に応じて価格が変動。
使いどころ・評価
- 使いどころ: アプリやWebサービスのUIデザイン案をスピード重視で出したいとき。開発チームがデザイナー不在でも、AIの提案でざっくりした画面イメージを固められる。
- 強み: 実際に編集可能なUI構造を生成するので、あとから要素を変更しやすい。従来の画像生成AIではできなかったボタンやメニューの配置を自動で考慮してくれる。
- 弱み: 細かいデザインルールやブランディングを落とし込むには、Figma等で再調整が必要。まだβ版で不安定な部分もある。

概要・特徴
2023年登場の画像生成AIで、テキスト要素を含むデザインが得意(他の画像AIだと文字が崩れる問題が多かった)。広告バナーやポスターなど、見出し文字・キャッチコピーを画像内に描写したいシーンで力を発揮。手書き風やポップ体などフォント調も指示可能。表示される文字のクオリティはまだ完璧ではないが、既存モデルよりも高い成功率を誇る。
料金・利用形態
ベータ版無料(要アカウント)。将来的に月額プランやクレジット制になるとの発表あり。WebUIからプロンプトを入力し、生成結果をダウンロード可。著作権は利用規約で要確認。
使いどころ・評価
- 使いどころ: ポスターやチラシに大きな文字を入れたい、ロゴやタイトル文字をAIで作りたい等。
- 強み: 文字を含むデザインが比較的破綻しにくく、従来の画像AIが苦手だった領域をカバー。
- 弱み: 全体的にまだ実験的で、フォントや文字の整合性が100%完璧ではない。日本語テキストは英語に比べると不安定。
デザインAIツールは、単体で利用するよりも、複数のツールを戦略的に組み合わせることで真価を発揮します。ECビジネスにおける具体的な活用例は以下の通りです。
- 基本ワークフロー: 「テンプレート × 自動レイアウト × AI生成画像」が鉄板の組み合わせです。まずCanva AIやMicrosoft Designerのテンプレートで基本的なレイアウトを固め、背景や装飾用の画像をMidjourneyやDALL-E 3で生成し、それを配置・編集するという流れが最も効率的です。
- 商品バナー・SNS投稿: Canva AIを使えば、一つのコンセプトから複数のデザインバリエーションを瞬時に生成し、A/Bテストに活用できます。文字入りの広告であれば、Ideogram AIで生成した画像をCanvaで仕上げるのも有効です。
- LP・UIデザイン: Gammaを使ってLPや企画書の構成案をスライド形式で素早く作成し、具体的なUIデザインはGalileo AIでモックアップを生成、最終的な仕上げはFigmaで行う、といった分業が考えられます。
- 戦略立案・アイデア整理: 新商品のコンセプトやマーケティング戦略を練る際には、NapkinAIでブレインストーミングを行い、アイデアを視覚的にマッピングすることで、チーム内の合意形成を円滑に進めることができます。
- ブランドガイドラインとの連携: 多くのツールのProプランでは、ブランドカラーやフォントを登録しておくことで、AIが生成するデザインを自動的にブランドの規定に準拠させることができます(Canva, Adobe Fireflyなどが対応)。
これらのツールを導入する最大のメリットは、外注費やデザイナーの工数を削減しつつ、デザイン制作のサイクルを高速化できる点にあります。AIに85%までを任せ、残りの15%の微調整を人間が行うことで、コストパフォーマンスを最大化できるでしょう。
6-7. 検索系AI
物販ビジネスの現場では、競合他社や商品の最新情報をいかに素早くキャッチし、適切に分析するかが重要な鍵となります。従来の検索エンジンでも情報収集はできましたが、生成AIの対話力を組み込んだ“検索系AI”なら、必要な情報を要点まとめ付きで抽出したり、対話形式で追質問したりと、より柔軟かつ効率的にリサーチを進められる可能性があります。本節では、Perplexity AI / Felo / GenSparkの3サービスを紹介し、それぞれの特徴や最新情報を整理します。なお、いずれのサービスにも「検索精度にムラがある」「最新トレンドや専門情報に弱い」などの課題が指摘されており、最終的な判断は常に人間の裏付けが必須です。
6-7-1. Perplexity AI
概要・特徴
LLMを活用した対話型の検索エンジン。Web上のニュース記事やブログなどを横断的に参照し、要約された回答を生成します。最大の特徴は、回答の各部分に参照元のリンク(出典)が明記されるため、情報の裏付けが取りやすい点です 。2025年からは、複数の情報源を統合して詳細なレポートを作成する「Deep Research」モードも追加され、より専門的な調査に対応できるようになりました 。
料金・利用形態
- 無料 (Standard) プラン: 無制限のクイック検索と、1日あたり5回のPro検索(高度な検索)が可能です 。
- Proプラン (月額 20ドル): 1日300回以上のPro検索、GPT-4やClaude-3などの高度なAIモデルへのアクセス、無制限のファイルアップロード、画像生成機能、月5ドル分のAPIクレジットなどが含まれます 。
- Enterprise Proプラン (月額 40ドル/シート〜): Proプランの全機能に加え、組織内でのファイル共有・検索、SSO(シングルサインオン)連携、強化されたデータプライバシー保護、専用サポートなどが提供されます 。
使いどころ・評価
- 強み: 出典リンクが明示されるため情報の信頼性を確認しやすく、リサーチ業務に最適です 。Proプランの「Deep Research」機能は、競合分析や市場調査で詳細なレポートを生成する際に強力なツールとなります 。
- 弱み: 無料版では高度な検索回数が厳しく制限されており、本格的な利用にはProプランが必須です 。

概要・特徴
2024年に登場した新興の検索AI。ChatGPT系エンジン+独自インデックスにより、対話形式でのリサーチを実現。 SNS投稿なども一定範囲で解析でき、リアルタイムのトレンド監視を重視。 プレゼン資料の自動生成やマインドマップ作成など、情報整理・発信までカバーする機能が特徴的。 多言語対応を前提としており、日本語での操作も比較的自然なやりとりが可能。
料金・利用形態
無料プラン:ユーザー登録後、基本AI検索は無制限。高度検索は1日5回までなどの制限あり。 プロフェッショナルプラン:月額2,000円台で、1日数百回の高精度検索や高度なAIモデル利用が可能。プレゼン作成機能も無制限。 商用利用:企業向けAPIやライセンスは検討中で、現時点では個別問い合わせが必要。
使いどころ・評価
検索精度:独自インデックスは充実度にムラがあるが、一般話題やSNS関連トピックは比較的強い。 要約の正確さ:文章要約・ポイント抽出は比較的安定。 UI操作性:チャット画面+資料化機能がユニーク。日本語にも対応しやすい。 強み: SNS解析で最新トレンドを拾いやすい/多言語対応が自然/資料作成機能で情報を即整理 弱み: 独自インデックスが限定的で専門情報に弱い傾向/ベータ版ゆえ仕様変更が多い/法人向けプランが未確定
6-7-4. まとめ――現時点での強みと注意点
対話型の検索AIは、従来のリサーチ手法を大きく変える可能性を秘めていますが、まだ発展途上の技術です。
- 信頼性と裏付けを最優先するなら: 出典リンクが明確なPerplexity AIが最適です。法人向けプランも整備されており、チームでの本格導入にも対応できます 。
- SNSのリアルタイムトレンドを追うなら: SNS解析と資料作成機能を持つFeloがユニークな価値を提供します。
いずれのサービスを利用する上でも、AIが生成した要約が常に正しいとは限らないという「誤情報リスク」を念頭に置く必要があります。AIの回答はあくまでリサーチの出発点と捉え、必ず参照元の一次情報にあたってファクトチェックを行うことが、ビジネスにおける責任あるAI活用と言えるでしょう。また、各サービスは頻繁に仕様変更や料金改定が行われるため、導入を検討する際は、必ず公式サイトで最新の利用規約を確認してください。
6-8. AIエージェント
2025年、生成AIは単に質問に答えたりコンテンツを作成したりするツールから、自律的に計画を立て、複数のツールを駆使してタスクを能動的に実行する「AIエージェント」へと進化を遂げています 。この新しい潮流を代表する存在として、GenSparkとManusという2つのプラットフォームが注目されています。両者は、自律型エージェントの構築において異なる哲学とアプローチを採用しており、その比較はAIの未来を占う上で重要です。
6-8-1. GenSpark
概要・特徴
GenSparkは、複数の特化型AIを統合管理する「Mixture-of-Agents(エージェント混合)」アーキテクチャを特徴とするプラットフォームです 。このシステムは、9つの異なるLLMと80以上の独自ツールを統合し、タスクの計画立案と推論の中核としてAnthropic社のClaudeを採用しています 。
GenSparkの最大のアプローチは、ウェブサイトを人間のように操作するのではなく、APIを通じて各種サービスと直接連携する「APIファースト」戦略です 。これにより、予約システムやデータベースとの高速で信頼性の高いデータ連携が可能となり、特にビジネスプロセスの自動化において高い安定性を発揮します 。
さらに、AIが人間のように電話をかけて予約や在庫確認を行う独自の音声通話機能や、調査結果をインタラクティブな単一ページにまとめる「Sparkpages」機能、プレゼンや動画の自動生成など、デジタルと現実世界を繋ぐ多彩な能力を備えています 。
料金・利用形態
GenSparkは、無料プラン(1日200クレジット)とプラスプラン(月額約25ドルで10,000クレジット)を提供するフリーミアムモデルを採用しています。しかし、その一方で「GenSpark AI Agent」という名称の暗号資産トークンが存在したり 、第三者のマーケットプレイスでサブスクリプションが販売されていたりと 、公式な支払い方法が不明瞭で混乱を招いています。
商用利用とAPI
GenSparkは法人利用を想定したマーケティングを行っていますが、その利用規約では生成されたコンテンツの利用を「個人的、非商業的な利用、または内部的なビジネス目的のみ」に限定しており、それ以外の商業利用には書面による許可が必要とされています 。これは、プラットフォームの価値提案と法的な利用条件の間に深刻な矛盾を生じさせており、商用利用を検討する企業にとって重大なリスクとなります。
また、開発者がGenSparkの機能を自社のアプリケーションに組み込むための公開APIや関連ドキュメントは、現時点では提供されていません。
強み・弱み
- 強み:
- API連携による構造化されたタスクの高速・高信頼な実行 。
- AIによる電話発信など、他にはないユニークな機能 。
- Sparkpagesやプレゼン、動画など、多彩なコンテンツ生成能力 。
- 弱み:
- 商用利用を制限する利用規約と、ビジネス向けマーケティングとの間の致命的な矛盾 。
- 価格体系が不明瞭で、複数の情報が錯綜している。
- 開発者向けの公開APIがなく、エコシステムが閉鎖的。

概要・特徴
シンガポールのスタートアップMonicaが開発したManusは、「思考するだけでなく、行動する」ことを目指す自律型AIエージェントです 。複数のAIモデルを連携させるマルチエージェントシステムを採用し、ユーザーがオフラインでもクラウド上で自律的にタスクを実行し続ける非同期実行が可能です 。
特にEコマース分野に注力しており、B2BサプライヤーのソーシングやSEO最適化、インタラクティブなウェブサイトの構築といったユースケースをアピールしています 。また、「Manusのコンピュータ」と呼ばれる機能を通じて、エージェントの作業プロセスをリアルタイムで可視化し、透明性を確保しようとしている点も特徴です 。
料金・利用形態
Manusはクレジットベースの料金体系を採用しており、スタータープラン(月額39ドルで3,900クレジット)やプロプラン(月額199ドルで19,900クレジット)などが確認されています 。しかし、このシステムの最大の問題点は、タスクが成功したかどうかに関わらず、実行されただけでクレジットが消費される点です。
商用利用とAPI
商用利用に関する明確な規約は確認されていませんが、Eコマースなどビジネス用途を強く意識した機能を提供しています 。開発者向けの公開APIは提供されていませんが、将来的には技術スタックの一部をオープンソース化する計画があるとされています 。
強み・弱み
- 強み:
- 人間のようにウェブを操作し、タスクを完遂するという野心的なビジョン 。
- Eコマースに特化した具体的なユースケースの提示 。
- 「Manusのコンピュータ」による作業プロセスの可視化 。
- 弱み:
- 深刻な安定性の問題: ユーザーからは、頻繁なクラッシュ、タスクのループ、サーバー過負荷が多数報告されており、信頼性が著しく低い状態です 。
- 不公平なクレジットシステム: タスクが失敗してもクレジットが返還されず、プラットフォームの不安定さのコストをユーザーが負担する構造になっています。あるユーザーは、8,555クレジットを消費したタスクが40%未満しか完了しなかったと報告しています 。
- 運用上の限界: CAPTCHA認証やペイウォールを突破できず、多くのウェブサイトで自律的な操作が妨げられます 。
- 「ラッパー」疑惑: 独自の革新的技術というより、既存のAIモデルを組み合わせた「ラッパー」に過ぎないとの批判があります 。
GenSparkとManusは、自律型AIエージェントの異なる可能性を示していますが、どちらも商用利用には大きな課題を抱えています。
- GenSparkは、API連携を軸としたアプローチにより、技術的には比較的安定した動作が期待できます。しかし、商用利用を厳しく制限する利用規約と、不明瞭な価格体系が、ビジネス導入の大きな障壁となっています。
- Manusは、人間のようにウェブを操作するという壮大なビジョンを掲げていますが、現状ではシステムの安定性が著しく低く、タスクの失敗率も高いです。さらに、失敗したタスクにも課金されるクレジットシステムは、ユーザーにとって極めてリスクが高く、実用的とは言えません。
2025年現在、AIエージェント市場はまだ黎明期にあります。派手なデモンストレーションや野心的な機能よりも、信頼性と予測可能性こそが、ビジネスでAIエージェントを導入する上で最も重要な評価基準となります。特に、ミッションクリティカルな業務を任せるには、安定した成果を一貫して提供できる能力が不可欠です。
EC事業者がこれらのツールを検討する際には、宣伝文句を鵜呑みにせず、小規模なテストを通じて実際のパフォーマンスを検証し、利用規約、特に商用利用の可否とコスト構造を精査する批判的な視点が求められます。
実践編:はじめに
生成AIが急速に注目を集めるなか、前半「理論編」では、AIの歴史や仕組み、そして「AIをどう捉え・どう付き合うか」という本質的な視点を掘り下げました。そこでは「AIは超優秀な新入社員」というアナロジーが繰り返し出てきたように、AIと人間の協業にこそ大きな可能性があるとお伝えしたと思います。
一方でビジネスの現場、とりわけ物販やECの世界では、「実際に何をどう指示すればいいのか?」「ほんとに自分の仕事で役立つのか?」といった疑問がつきまとうのも事実です。AIが理論上どれだけ賢くとも、我々が具体的に使いこなすためのノウハウがなければ、ただの“宝の持ち腐れ”になってしまいます。
そこで本書「実践編」では、より実務寄りの
- 相場リサーチ
- 競合分析
- 商品の最安値リサーチ
- 商品説明文や営業メールの自動生成
- 画像の作成
- 在庫管理ツールの作成
…など、物販ビジネスで「すぐに試せて成果が出やすい」活用事例を順序立てて紹介していきます。
実践編のポイントは、読者が実際にAIツールを動かしながら学べるように、各章でプロンプト例や画面イメージを示し、仕上がりをチェックして微調整する手順をお見せすることです。理論編で習得した「AIはツールではなく部下・同僚のような存在」という考え方を活かしながら、「こういう前提を伝えれば、AIがより正確にアウトプットしてくれる」という実践のコツをつかんでいただければと思います。
【注意点】
実践編ではAIの使い分けにはほとんど言及しません。理由は以下の通り。
- 特定のAIについて言及しても、仕様変更がされたり後発のAIが登場する可能性がある
- 同一機能を有しているAIでは、AIの機能差よりも、プロンプトを入力する人間のスキルの方が出力に影響する
- 「今どのAIが有用かを知ること」よりも、「とりあえずどのAIでもいいからトライしてみる瞬発力」の方が、群雄割拠のAI時代においては重要なスキルである
実践編第1章 AIで相場リサーチする
まず第1章では、相場リサーチにフォーカスします。
これまで相場調査といえば、手動検索や専用ツールで同じ型番の落札価格を一覧化したり、「ジャンク」とひとくちに言っても詳細コンディションが分からずに戸惑うなど、人間側での手間や微妙な判定が大きな負担でした。
AIを使うと、厳密な数値を確定的に得られるとは限らないものの、「そういえば付属品がない場合はどうなのか」や「こんな視点でもデータを拾ったらどう?」といった“提案力”や“柔軟性”が期待できるのが大きな強みです。
言い換えれば、従来のツールが苦手とする「事例に合わせた変動要素」や「あいまいな状態の解釈」をAIにヒアリングさせることで、思わぬ切り口のデータを手軽に探れるのです。
さあ、いよいよ「理論→実践」の橋渡しとして、本編の第1章へ進みましょう。
ここからは実務レベルのサンプルを具体的に示し、「プロンプト例→AI出力→そこに対してさらに指示→最終チェック・活用法」というプロセスを段階ごとに解説していきます。きっと、ご自身の物販リサーチでも「こういうふうに使えばいいのか!」と実感していただけるでしょう。
1-1.なぜ相場リサーチをAIでやるのか?
物販ビジネスにおいて、自分が扱う商品の価格帯を理解し、市場の動きを把握することは必須です。特に中古市場の場合、コンディションの差や付属品の有無、修理歴の有無など、単純に型番だけでは測れない要素がたくさんあります。
これまでも相場調査に使える専用ツールは存在しましたが、たとえば「ヤフオクの落札履歴を一覧化するツール」や「メルカリの売れた値段をグラフ化するサービス」など、それぞれ動作範囲が限定されているケースが多いのが実態です。そのようなツールを「従来ツール」と呼ぶなら、以下のような特徴があるでしょう。
- 従来ツールの強み
- 特定のプラットフォームや条件(カテゴリ・型番など)で、ある程度確定的な数値を一括抽出してくれる
- 過去の落札価格や出品数、平均落札額は、スクレイピング結果としてある程度正確に把握
- 従来ツールの弱み
- 「ジャンク」や「B品」など、抽象的なコンディションの差異を人間が判断しないといけない
- 付属品の欠品や動作のクセなど、ツール側が認識しない不確定要素を拾いきれない
- 購入者視点の独自の見方(「使用回数が何回」「箱が破損している」など)を反映しにくい
ここでAIの“柔軟性”と“提案力”が活きてきます。ChatGPTやGeminiのような「会話型AI」は、単に数値だけ取ってくるのではなく、
「この商品、付属品が欠品してるらしいけど、同等品でも売れる可能性は?
競合商品のレビューを見ると、付属品なしでもこの価格帯で売れている例があるみたい。
よかったら、参考URLも拾ってみる?」
といった、不確定な要素の解釈や追加提案を行いやすいのです。もちろん、最新データの精度や真偽は必ず最終チェックが必要になりますが、従来ツールが拾えない“ゆらぎ”や“応用的な話題”を一緒に考える相棒としては非常に心強い存在と言えるでしょう。
要するに、相場リサーチをAIで行う最大の理由は、
- 複数プラットフォーム・複数条件をまたいだデータを横断的に拾いやすい
- 定量情報(落札価格や販売価格)に加え、定性情報(使用感、説明文のニュアンス)も取り込める
- 厳密さは専用ツールに劣る面もあるが、“それ以外の柔軟な指標”を見つけるのが得意
このように、人間側が「ジャンク商品ってどんな状態?」「付属品なしの場合の相場は?」など“ざっくりとした質問”を投げかけても、AIは工夫して回答してくれます。ツール×AIを組み合わせて使うことで、さらに効率良く相場を深掘りできるわけです。
1-2.検索系AIの使いどころ──Perplexity / GenSpark / Felo / ほか
AI検索ツールとChatGPT系「DeepResearch」の二段構え
実際に相場調査をするとき、検索特化のAI(Perplexity、GenSpark、Feloなど)を併用すると便利です。これらはWeb上のニュース記事や出品情報を検索してくれたり、一部SNS投稿まで拾って要点をまとめたりします。
ポイント:
- 検索AI(Perplexityなど)で「最新の出品状況」や「参考リンク」をざっと拾う
- ChatGPT/Geminiに、検索結果のURL・要点を再整理させる
- 「コンディション別の価格を分類して」「付属品あり/なしを比較して」と追加指示
たとえば、GenSpark は“AIスタートアップが独自に構築したインデックス”をベースに、要約やサマリーを出してくれると言われていますが、まだ抜けや偏りはありそうです。
そのため、どこまで拾えているかは都度チェックが必要ですが、「思わぬ視点」を教えてくれることもあるので、従来ツールとは別の角度から調査が可能になります。
1-3.商品コンディション別・販売チャネル別の価格整理
1-3-1.実演フロー- プラットフォームの指定
- 「Amazon」「楽天市場」「メルカリ」「ヤフオク」など、複数販路を挙げてAIにリサーチさせる
- 「最近6か月の平均売価を教えて」「最低落札価格の分布を把握したい」など、具体的に言う
- コンディションの指定
- 「未使用A」「使用感ありB」「ジャンクC」など自分が使いたい区分を事前にAIへ伝える
- 「BとCの境界が曖昧だから、目安を3点くらい挙げて」と頼むのもOK
- リサーチ件数や終了条件を指定
- 「各プラットフォーム◯件ずつ取得」「平均価格の変化が◯%以下になるまで価格を取得」など、条件を指定する
- 出力を見て微調整
- 「付属品がないケースも調べて」「キズ・凹みのある出品例を探して」など、さらに掘り下げ
1-3-2.実際のプロンプト例
生成AIは「相場をリサーチして」といった短い指示だと毎回挙動が変化してしまいます。「従来のツール」と異なり、生成AIには詳細に指示を出さないと再現性を高めることはできません。「従来のツール」であれば決まったパラメーターに数値やキーワードを設定することで毎回同様のリサーチを実行することができますが、生成AIでのリサーチの場合は、リサーチの手順や取得した数値の扱いまで指定する必要があります。
以下は実際にリサーチする際のプロンプト例です。
以下のステップと条件を満たす形で調査・分析を行い、結果をまとめてください。
1. 調査範囲・条件
# 対象商品: エプソン EP-10VA
# コンディション: D
# 付属品: インクなし
# 対象販路: メルカリ・ヤフオク・Yahoo!フリマ・ラクマ
# 期間: 直近12か月の売上実績または落札履歴
# データ収集基準:
全販路合計で最低20件以上の同コンディションの売却/落札実績価格を取得
1つのプラットフォームから十分な件数が集まらない場合は、他のプラットフォームと合算
最大件数は合計100件を目安とする(各販路で最大25件 × 4)
# 価格データのばらつき:
取得データから外れ値(平均 ± 2σを超えるものなど)を除外
標準偏差が平均価格の20%未満に収まるまで、可能な範囲で追加データ取得(最大120件まで)
それでも標準偏差が20%を超える場合は、ばらつきが大きいことを明記
#コンディション基準:
未使用に近い(A):開封済みだが未使用、または試用程度で傷や汚れなし
目立った傷や汚れなし(B):使用感はあるが、大きなダメージなし
やや傷や汚れあり(C):目立つ傷や汚れがあるが、通常使用可能
傷や汚れあり(D):動作に問題はないが、かなり使用感がある
ジャンク(E):動作保証なし、または一部不具合あり
2. 分析・算出方法
# データの収集
メルカリ・ヤフオク・Yahoo!フリマ・ラクマから取得し、プラットフォームを区別せずに合算
出品タイトルや説明文から、コンディションDと付属品がインクなしであることを確認
必要に応じて画像や説明文で動作に問題がないことを確認
# 外れ値の除去
合算データの「平均価格」を算出
平均 ± 2σ(標準偏差)の範囲から外れたデータを「外れ値」として除外
外れ値除外後に新たな平均価格と標準偏差を計算し直す
標準偏差が一定以下に収まるまで繰り返し(可能な範囲で)
もし標準偏差(σ) が「再計算後の平均価格 × 0.2(20%)」を超える場合は、追加データを探して再集計
上限(合計100件)に達しても20%を超える場合は、「価格に大きなばらつきがある」として考察を示す
#結果の算出・まとめ
最終的な平均価格: ○○円
価格帯(最小値 ~ 最大値): ○○円 ~ ○○円
標準偏差: ○○円
データ件数: ○○件(外れ値除外前と後の件数も比較表示)
参考リンクやソース: 可能な限りURLを示す
付属品の違いによる影響など、価格差要因が明確であれば補足
3. 出力形式
表形式
合算データについて
「最終件数(外れ値除外前後の数)」
「最小価格 ~ 最大価格」
「平均価格」
「標準偏差」
必要に応じて参考URLをリストアップ
ばらつきが大きい場合はその旨や考えられる要因を簡潔に補足
1-3-3.出力結果:ChatGPT o1 pro with Deep Research
このプロンプトをChatGPTに入力し、「詳細なリサーチ(Deep Research)」を行いました。
出力にかかった時間は14分。

取得できたデータ件数は23件で、AIいわく「コンディションDなら大体11,500円前後で取引されている」とまとめています。
ただし、もちろん精度にはバラつきがあるため、具体的なURLを参照して
「本当にそんな価格で取引されているのか?」
という二次確認が必要になります。AIの結果を鵜呑みにせず、リンク先の商品説明や画像を実際に確認しながら、本当に同じようなコンディションなのかを自分の目でチェックすることが不可欠です。
1-3-4.出力結果:Felo Pro Search (GPT-4o) with Deep Research
続いて、同様のプロンプト(調査条件)をFelo Pro Searchに入力し、GPT-4oエンジンを用いた詳細リサーチを実行。
こちらの出力にかかった時間は数十秒と短く、素早く結果が返ってきました。


取得したデータ件数は56件で、先ほどのChatGPT o1 proの約2倍以上。価格情報の集計結果を見てみると、11,000円~15,000円の範囲で取引される事例が中心で、最終的な平均価格としては13,200円が導き出されました。
1-4.AIごとの結果の違い──なぜ生じる?どう活用する?
先ほどのChatGPT o1 proでは「平均約11,500円」という推定でしたが、Felo Pro Search (GPT-4o) では「平均約13,200円」と、1,700円ほど高めに結果が出ています。
この差はどこから生まれるのでしょうか?主な要因として、以下の可能性が考えられます。
- データ取得範囲の違い
- ChatGPT o1 proは23件のデータを取得したのに対し、Felo Pro Searchは56件と倍以上の情報を収集。
- 商品説明文・動作確認の解釈の違い
- AIが各出品の説明文をどう解釈するかによって、コンディションDと判断するかE(ジャンク)と判断するか、またはC寄りと判断するかの微妙な誤差が生じることがあります。
- その結果、本来は「動作未確認でジャンク扱い」の出品が「動作問題なし」に分類され、平均価格を押し上げるケースも考えられます。
このように、AIごとに集計結果が変化するのは“当然”とも言えます。
逆に複数のAIやツールで同様の調査を行い、結果を比較することで、相場に関するより立体的な理解が得られるわけです。
- ChatGPT o1 proの結果:
- 平均価格:11,500円前後
- データ件数:23件
- 時間:14分
- Felo Pro Searchの結果:
- 平均価格:13,200円前後
- データ件数:56件
- 時間:数十秒
いずれの結果も、「11,000円~15,000円が価格の主なレンジ」である点は共通しています。
では、実際に出品や仕入れの際、どの程度を目安とすればいいかというと、「12,000円~14,000円」を狙うのが無難かもしれません。
1-5.相場リサーチのプロンプトの書き方
プロンプトの作成は次のような7ステップで行います。
ステップ1.やりたいこと(ゴール)を明確化するまず、プロンプトの最終ゴールをはっきりさせましょう。「相場調査をしてほしい」だけだとAIの解釈があいまいになります。この例では、
ゴール:「対象商品(エプソン EP-10VA / コンディションD / インクなし)について、直近12か月の相場を調査・分析し、表形式でまとめてほしい」
という明確な目標があります。どのプラットフォームで、どんな期間のデータを、どう分析して、どんな形式で出力してもらうかを一つひとつ書き出すのがポイントです。
ステップ2.調査範囲と条件を箇条書きで指定する
AIがどこまで検索すればいいのか、どんな条件で検索すればいいのかを“箇条書き”で具体的に示します。今回の例では以下のように指定しています。
1. 調査範囲・条件
# 対象商品: エプソン EP-10VA
# コンディション: D
# 付属品: インクなし
# 対象販路: メルカリ・ヤフオク・Yahoo!フリマ・ラクマ
# 期間: 直近12か月の売上実績または落札履歴
# データ収集基準:
- 全販路合計で最低20件以上の同コンディションの売却/落札実績価格を取得
- 1つのプラットフォームから十分な件数が集まらない場合は、他のプラットフォームと合算
- 最大件数は合計100件を目安とする(各販路で最大25件 × 4)
ポイント:
- 「対象商品」や「コンディション」をハッキリ書く
「商品名」「型番」「使用状態(D)」などを具体的に記載。 - 「対象販路」や「期間」を明確化
メルカリ・ヤフオクといったフリマ/オークションサイトなのか、何カ月分なのかを書いておく。 - 「取得すべきデータ件数」や「合算のルール」を書く
例:「合計20件以上は確保する」「最大100件」など。
こうすることで、AIが“どこ”から“どれくらいのデータ”を取ればいいのかを理解しやすくなります。
ステップ3.分析方法・算出方法を細かく書く次に、集めたデータをどう処理してほしいのかを、分析手順として明示します。
ここが不十分だと、AIが勝手に自分流の分析をしてしまい、思ったのと違う結果になる可能性が高いです。
2. 分析・算出方法
# データの収集
- メルカリ・ヤフオク・Yahoo!フリマ・ラクマから取得し、プラットフォームを区別せずに合算
- 出品タイトルや説明文から、コンディションDと付属品がインクなしであることを確認
- 必要に応じて画像や説明文で動作に問題がないことを確認
# 外れ値の除去
- 合算データの「平均価格」を算出
- 平均 ± 2σ(標準偏差)の範囲から外れたデータを「外れ値」として除外
- 外れ値除外後に新たな平均価格と標準偏差を計算し直す
- 標準偏差が一定以下に収まるまで繰り返し(可能な範囲で)
- もし標準偏差(σ) が「再計算後の平均価格 × 0.2(20%)」を超える場合は、追加データを探して再集計
- 上限(合計100件)に達しても20%を超える場合は、「価格に大きなばらつきがある」として考察を示す
ポイント:
- 「データの収集方法」を指定
例:「プラットフォームごとのデータを合算」「タイトルや説明文から状態を判断」など。 - 「外れ値(オーバーシュートや極端に安い取引)」の定義・除外方法を具体的に書く
例:「平均 ± 2σ」の基準を使うなど。 - 「標準偏差の扱い」を明確化
例:「標準偏差が平均価格の20%を超える場合は再調査」など。
これらをきちんと指定しておくことで、AIがどのように数値を取り扱い、何回計算を繰り返すかを誤解なく伝えられます。
ステップ4.コンディション基準を表にして示す商品状態(コンディション)の基準を明確に定義することで、AIが誤って「ジャンク」や「未使用」などを混同しないようにします。
今回の例では、A~Eの5段階を用意し、その中でDの定義を「動作に問題ないが、使用感はかなりある」と設定しています。
#コンディション基準:
- 未使用に近い(A):開封済みだが未使用、または試用程度で傷や汚れなし
- 目立った傷や汚れなし(B):使用感はあるが、大きなダメージなし
- やや傷や汚れあり(C):目立つ傷や汚れがあるが、通常使用可能
- 傷や汚れあり(D):動作に問題はないが、かなり使用感がある
- ジャンク(E):動作保証なし、または一部不具合あり
ポイント:
- 各コンディションの定義を具体的に
AIが商品説明文などから状態を判断するときの基準を明確化すると、分類ミスが減ります。
- 自分が使うランク表記(A, B, C, D, Eなど)をはっきり書く
「D=こんな状態」をちゃんと説明するだけで、AIが出品情報を処理するときに役立ちます。
ステップ5.最終的に出力してほしい項目を整理
「どんな項目を、どんな形式(表形式など)で出してほしいか」を指定します。これもあいまいだと、AIが文章でダラダラと書いてしまい、欲しい数値が埋もれてしまいます。
3. 出力形式
- 表形式
- 合算データについて
- 「最終件数(外れ値除外前後の数)」
- 「最小価格 ~ 最大価格」
- 「平均価格」
- 「標準偏差」
- 必要に応じて参考URLをリストアップ
- ばらつきが大きい場合はその旨や考えられる要因を簡潔に補足
ポイント:
- 出力を箇条書きで要求すると、AIがわかりやすい形で返してくれやすい
- 「外れ値除外前の件数」「外れ値除外後の件数」など、分析で比較したい指標も指定
- 「表形式で出して」「URLも可能なら出して」などレイアウトの希望を入れる
これで、可読性の高い結果が得られやすくなります。
ステップ6.「一連の手順」をプロンプトとしてまとめる以上の要素をすべてひとつのプロンプトにまとめておけば、AIは「何を」「どう処理し」「どう出力するか」を理解しやすくなります。
実際には、以下のようにマークダウンや箇条書きで順番どおりに書くだけです。
例:まとめのプロンプト全文
以下のステップと条件を満たす形で調査・分析を行い、結果をまとめてください。
1. 調査範囲・条件
# 対象商品: エプソン EP-10VA
# コンディション: D
# 付属品: インクなし
# 対象販路: メルカリ・ヤフオク・Yahoo!フリマ・ラクマ
# 期間: 直近12か月の売上実績または落札履歴
# データ収集基準:
- 全販路合計で最低20件以上の同コンディションの売却/落札実績価格を取得
- 1つのプラットフォームから十分な件数が集まらない場合は、他のプラットフォームと合算
- 最大件数は合計100件を目安とする(各販路で最大25件 × 4)
# 価格データのばらつき:
- 取得データから外れ値(平均 ± 2σを超えるものなど)を除外
- 標準偏差が平均価格の20%未満に収まるまで、可能な範囲で追加データ取得(最大120件まで)
- それでも標準偏差が20%を超える場合は、ばらつきが大きいことを明記
#コンディション基準:
- 未使用に近い(A):開封済みだが未使用、または試用程度で傷や汚れなし
- 目立った傷や汚れなし(B):使用感はあるが、大きなダメージなし
- やや傷や汚れあり(C):目立つ傷や汚れがあるが、通常使用可能
- 傷や汚れあり(D):動作に問題はないが、かなり使用感がある
- ジャンク(E):動作保証なし、または一部不具合あり
2. 分析・算出方法
# データの収集
- メルカリ・ヤフオク・Yahoo!フリマ・ラクマから取得し、プラットフォームを区別せずに合算
- 出品タイトルや説明文から、コンディションDと付属品がインクなしであることを確認
- 必要に応じて画像や説明文で動作に問題がないことを確認
# 外れ値の除去
- 合算データの「平均価格」を算出
- 平均 ± 2σ(標準偏差)の範囲から外れたデータを「外れ値」として除外
- 外れ値除外後に新たな平均価格と標準偏差を計算し直す
- 標準偏差が一定以下に収まるまで繰り返し(可能な範囲で)
- もし標準偏差(σ) が「再計算後の平均価格 × 0.2(20%)」を超える場合は、追加データを探して再集計
- 上限(合計100件)に達しても20%を超える場合は、「価格に大きなばらつきがある」として考察を示す
# 結果の算出・まとめ
- 最終的な平均価格: ○○円
- 価格帯(最小値 ~ 最大値): ○○円 ~ ○○円
- 標準偏差: ○○円
- データ件数: ○○件(外れ値除外前と後の件数も比較表示)
- 参考リンクやソース: 可能な限りURLを示す
- 付属品の違いによる影響など、価格差要因が明確であれば補足
3. 出力形式
- 表形式
- 合算データについて
- 「最終件数(外れ値除外前後の数)」
- 「最小価格 ~ 最大価格」
- 「平均価格」
- 「標準偏差」
- 必要に応じて参考URLをリストアップ
- ばらつきが大きい場合はその旨や考えられる要因を簡潔に補足
ステップ7.細かい表現を調整して、AIにわかりやすくする
最後に、プロンプトの文言をシンプルにするか、具体的な例を加えるなどして、AIがうまく理解しやすい表現に調整します。
- たとえば「ジャンク品に近いDは拾わないで」など条件を追加したいときには、#コンディション基準のところで「DとEの境界はこうする」と詳しく書き足します。
- 逆に「ガッツリ英語の文法で書きたい」場合は英語ベースで書き換えるなど、自分の好みに調整可能です。
AIによっては自然言語が得意な場合もあれば、数式や箇条書きが得意な場合もあるので、最適な書き方はツールによって微妙に異なることも覚えておきましょう。
相場リサーチプロンプトの作成方法まとめ
- (1) ゴールを決める:「何をどう出力してほしいか」を明確化
- (2) 調査範囲と条件を箇条書きで指定:「対象商品」「コンディション」「期間」「取得件数」など
- (3) 分析方法を細かく書く:「外れ値の定義」「標準偏差の扱い」「繰り返し条件」など
- (4) コンディション基準を明示する:AIが商品状態を誤認しないように基準表を書いておく
- (5) 出力形式を指定する:欲しい結果を箇条書きや表形式でまとめてもらう
- (6) 一連の手順を一つのプロンプトにまとめる:セクション分け、見出し、箇条書きを活用
- (7) 文言を整えて最終チェック:AIが読みやすい形式に落とし込む
これらのステップを踏めば、初心者の方でも同じプロンプトを再現しやすくなり、安定した分析結果を得ることが期待できます。
1-6. 相場リサーチのプロンプトテンプレート
以下のプロンプトを“テンプレート”として使い回せる形にしました。
必要に応じて、【〇〇を入れてください】 の部分を自分の状況に合わせて変更してご利用ください。
使い方(テンプレートの記入例)【テンプレート:相場調査&分析プロンプト】
以下のステップと条件を満たす形で調査・分析を行い、結果をまとめてください。
1. 調査範囲・条件
# 対象商品: 【商品名や型番を入れてください】
例)エプソン EP-10VA
# コンディション: 【A / B / C / D / E などの設定を入れてください】
例)D
# 付属品: 【「インクなし」「箱なし」など、調査対象にする付属品条件を記入】
# 対象販路: 【複数プラットフォームを指定してください】
例)メルカリ・ヤフオク・Yahoo!フリマ・ラクマ
# 期間: 【どのくらいまでの売上実績・落札履歴を対象にするか】
例)直近12か月
# データ収集基準:
- 全販路合計で最低【 〇〇 】件以上の同コンディションの売却/落札実績価格を取得
(例:20件以上)
- 1つのプラットフォームから十分な件数が集まらない場合は、他のプラットフォームと合算
- 最大件数は合計【 〇〇 】件を目安とする(各販路で最大25件 × 4など)
価格データのばらつき(外れ値対応)の指示
# 価格データのばらつき:
- 取得データから外れ値(平均 ± 2σを超えるものなど)を除外
- 標準偏差が平均価格の【 〇〇 % 】未満に収まるまで、可能な範囲で追加データ取得(上限【〇〇件】)
- それでも標準偏差が【 〇〇 % 】を超える場合は、ばらつきが大きいことを明記
コンディション基準(任意で細かく指定したい場合)
# コンディション基準:
- 未使用に近い(A):開封済みだが未使用、または試用程度で傷や汚れなし
- 目立った傷や汚れなし(B):使用感はあるが、大きなダメージなし
- やや傷や汚れあり(C):目立つ傷や汚れがあるが、通常使用可能
- 傷や汚れあり(D):動作に問題はないが、かなり使用感がある
- ジャンク(E):動作保証なし、または一部不具合あり
2. 分析・算出方法
# データの収集
- 【指定した販路】から取得し、プラットフォームを区別せずに合算
- 出品タイトルや説明文から、【指定したコンディション】であることを確認
- 【付属品の有無】なども確認し、条件に合うものだけ抽出
- 画像や説明文で動作に問題がないかどうか、できる範囲でチェック
# 外れ値の除去
- 合算データの「平均価格」を算出
- 平均 ± 2σ(標準偏差)の範囲から外れたデータを「外れ値」として除外
- 外れ値除外後に新たな平均価格と標準偏差を計算し直す
- 標準偏差が一定以下に収まるまで繰り返し(可能な範囲で)
- もし標準偏差(σ) が「再計算後の平均価格 × 【 〇〇 % 】」を超える場合は、追加データを探して再集計
- 上限(合計【 〇〇 】件)に達しても【 〇〇 % 】を超える場合は、「価格に大きなばらつきがある」として考察を示す
3. 結果の算出・まとめ
# 結果の算出・まとめ:
- 最終的な平均価格: ○○円
- 価格帯(最小値 ~ 最大値): ○○円 ~ ○○円
- 標準偏差: ○○円
- データ件数: ○○件(外れ値除外前と後の件数も比較表示)
- 参考リンクやソース: 可能な限りURLを示す
- 付属品の違いによる影響など、価格差要因が明確であれば補足
4. 出力形式
# 出力形式
- 表形式
- 合算データについて
- 「最終件数(外れ値除外前後の数)」
- 「最小価格 ~ 最大価格」
- 「平均価格」
- 「標準偏差」
- 必要に応じて参考URLをリストアップ
- ばらつきが大きい場合は、その旨や考えられる要因を簡潔に補足
- 【対象商品】や【コンディション】、【付属品】など、自分が調べたい内容を記入
- 【期間】や【データ収集基準】を自分の目的に合わせてカスタマイズ
- 外れ値の基準や標準偏差の扱いも、必要に応じて「±2σ」→「±1.5σ」などに変更OK
- 出力形式も「表形式」「箇条書き」など好みに応じて微調整
- 最終的に完成したテンプレートをそのままAIにコピペし、「この条件で調査&分析して」と実行
これで、複数のAIツール(ChatGPTやGemini、Felo、Perplexity、Genspark など)を利用する際にも、同じ形式・同じ流れのプロンプトで相場リサーチを一貫して行うことができます。
1-7.1章のまとめ:AI相場リサーチのメリットと注意点
- メリット
- 複数販路の横断調査が自動化できる
- コンディションや付属品の有無など“曖昧”な要素を対話的に詰められる
- 新たな提案や観点(「カラバリが違うだけで価格差がある」など)をAIが示してくれる場合がある
- 注意点
- 数値は100%正確ではなく、ソースの更新タイミングでズレが生じる
- AIが不確定情報を堂々と語るリスク(いわゆる“ハルシネーション”)
- 最新履歴やニッチな取引履歴はそもそもWeb上に少なく、AIも拾えない場合がある
結局のところ、AIによる相場リサーチは「従来ツール+AI検索+人間の最終判断」の組み合わせで活きてきます。とりわけ中古品や複雑なコンディション差がある商材では、「え、このパーツ欠品でも意外と値がつくんだ」という気づきが得られたり、AIの提案力が大いに助けになるでしょう。
次章では、この「リサーチ力」をさらに拡張して、競合分析や差別化ポイントの洗い出しに活かしていきます。自分の扱う商品をどう改善し、何を強みに打ち出せばいいのか──AIとの対話を通じて、具体的な新製品の方向性を探る流れを見ていきましょう。
実践編第2章 競合分析を自動化する──商品開発や差別化のヒントを得る
この記事を紹介する
この記事のレビュー
5.0
(5)
ゴマちゃん
ECセラーしてます。 AIに詳しいです。
5
(5)
5.0
(5)
5.0
(5)